The 2026 market shift toward specialized models
The enterprise AI landscape in 2026 is defined by a decisive break from generic foundation models. As Laurie Voss notes in industry analysis, 2026 marks the year of fine-tuned small models, driven by the diminishing returns of relying solely on frontier capabilities. Organizations can no longer compete on access to raw intelligence; they must compete on the precision of their applied intelligence. This shift transforms AI from a commodity utility into a core differentiator, where proprietary data and specialized training dictate market advantage.
The baseline for enterprise deployment has evolved from simple chatbot interfaces to autonomous agentic systems. Generic models lack the contextual nuance and safety guardrails required for high-stakes operational workflows. Fine-tuning provides the necessary layer of enterprise-grade reliability, allowing models to execute complex, multi-step tasks with reduced hallucination rates. This move toward specialized models is not merely a technical upgrade but a strategic imperative to protect intellectual property and ensure regulatory compliance.
To visualize this divergence, the following chart illustrates the growing gap between generic LLM usage and the adoption of fine-tuned models in enterprise sectors. The trend confirms that while general-purpose AI plateaus, specialized applications continue to accelerate as organizations prioritize performance over breadth.
For teams beginning this transition, selecting the right tools is critical. The following resources provide practical guidance on implementing fine-tuning strategies effectively.



As an Amazon Associate, we may earn from qualifying purchases.
Fine-tuning costs drop below $5
The economic barrier to AI fine-tuning 2026 adoption has effectively collapsed. Driven by algorithmic efficiency gains like Low-Rank Adaptation (LoRA) and model quantization, the cost to fine-tune a 7-billion parameter model now sits under $5. This dramatic reduction transforms fine-tuning from a specialized, high-budget R&D exercise into a standard operational expense for enterprises.
Previously, training even small models required significant GPU hours and specialized infrastructure, pricing out all but the largest tech firms. Today, the marginal cost of adapting a base model to specific enterprise data is negligible. This shift allows companies to deploy highly specialized language models for customer support, legal review, and internal knowledge retrieval without incurring prohibitive infrastructure bills.
The affordability of small, fine-tuned models does not mean sacrificing performance. Quantization techniques allow these models to run efficiently on cheaper hardware or cloud instances, further driving down operational costs. The result is a market where bespoke AI capabilities are accessible to organizations of any size, provided they have the data to train them.
To capitalize on this cost efficiency, enterprises are increasingly building internal teams capable of managing these lightweight models. The focus has shifted from acquiring expensive proprietary APIs to curating high-quality datasets and implementing efficient fine-tuning pipelines. This democratization of AI capability is reshaping the competitive landscape, where data quality matters more than compute scale.
Managed Fine-Tuning Infrastructure
The enterprise shift toward AI fine-tuning in 2026 is defined by the platforms that abstract away the complexity of distributed training. Decision-makers are no longer evaluating raw model weights but the developer experience, model breadth, and enterprise support offered by managed infrastructure. The market has consolidated around providers that balance open-source flexibility with managed reliability.
Platform Comparison
The following comparison highlights the primary infrastructure providers enabling this shift. The focus is on model selection breadth, ease of integration, and support for enterprise-grade workloads.
| Provider | Model Selection | Developer Experience | Enterprise Support |
|---|---|---|---|
| Together AI | 200+ Open Source | Clean API | Standard |
| Premai | Broad | High-Level | Strong |
| Axolotl | Flexible | Config Wrapper | Reproducible |
| Lambda | Hardware Focused | Infrastructure | Custom |
Developer Experience and Model Breadth
Together AI stands out for its developer-friendly API and extensive selection of over 200 open-source models. This breadth allows enterprises to fine-tune a wide variety of architectures without being locked into a single vendor’s proprietary ecosystem. The clean API reduces the time from prototype to production, a critical factor in the fast-moving AI landscape.
Axolotl offers a different value proposition by providing a high-level configuration wrapper. It streamlines the end-to-end fine-tuning pipeline with an emphasis on reproducibility. For teams where auditability and consistent results are paramount, Axolotl’s approach ensures that fine-tuning processes can be reliably replicated across environments.
Enterprise Support and Infrastructure
For organizations requiring robust infrastructure, providers like Lambda focus on the underlying hardware and scalability. Their support is tailored for custom enterprise needs, offering the flexibility to manage large-scale training jobs. This is essential for finance and healthcare sectors where data sovereignty and performance are non-negotiable.
The choice of platform ultimately depends on the balance between ease of use and control. Managed platforms reduce operational overhead, while more flexible solutions offer greater customization. As AI fine-tuning becomes a core competency, the infrastructure layer must support both rapid iteration and rigorous compliance.
Hardware requirements for local fine-tuning
The shift toward local fine-tuning in 2026 is no longer a niche experiment; it is a strategic imperative for enterprises prioritizing data privacy and latency. As AI fine-tuning 2026 trends move away from massive, centralized data centers, the hardware barrier to entry has collapsed. Organizations can now deploy sophisticated models on accessible GPU setups, reducing operational costs while maintaining strict control over proprietary datasets.
The economic reality of this shift is stark. Fine-tuning a 7-billion parameter model now costs under $5, a figure that makes local deployment economically viable for mid-sized enterprises. This affordability is driven by more efficient hardware architectures and software optimizations that maximize GPU utilization. The result is a democratization of AI capabilities, where high-performance computing is no longer reserved for tech giants with unlimited capital.
| Component | Recommendation | Why It Matters |
|---|---|---|
| GPU | NVIDIA H100 / RTX 4090 | High memory bandwidth for large model weights |
| Storage | NVMe SSD (2TB+) | Fast data loading reduces training idle time |
| RAM | 64GB+ | System buffer for data preprocessing |
This transition does not mean abandoning cloud infrastructure entirely. Instead, enterprises are adopting a hybrid approach, using local hardware for sensitive fine-tuning tasks and cloud resources for inference scaling. This balance allows organizations to leverage the speed of local processing for development and iteration while maintaining the scalability of the cloud for production workloads.
The hardware landscape is evolving rapidly, with new GPUs offering better performance-per-watt and lower costs. Enterprises must stay informed about these developments to make strategic investments that align with their long-term AI goals. The key is not just having access to hardware, but optimizing its use to maximize ROI.
For teams building custom AI solutions, having the right hardware is just the beginning. The following products represent essential tools for setting up a local fine-tuning environment, ensuring that your infrastructure is ready for the demands of 2026.



As an Amazon Associate, we may earn from qualifying purchases.
As the market for AI hardware continues to grow, investors should watch for trends in GPU demand and pricing. The chart above reflects the recent performance of NVIDIA, a key player in the AI hardware space. Understanding these market dynamics is crucial for making informed decisions about hardware investments.
The move to local fine-tuning is not just about cost savings; it is about control. By keeping data on-premises, enterprises can mitigate privacy risks and ensure compliance with regulations. This shift represents a fundamental change in how AI is developed and deployed, with hardware playing a central role in enabling this new paradigm.
Enterprise fine-tuning implementation
The shift from generic LLMs to specialized models requires a disciplined workflow. In 2026, the baseline for enterprise AI has moved beyond simple chatbot interfaces to autonomous agentic systems, demanding precise data curation and rigorous evaluation [src-6]. A structured approach ensures that fine-tuning investments directly support business outcomes rather than serving as experimental exercises.
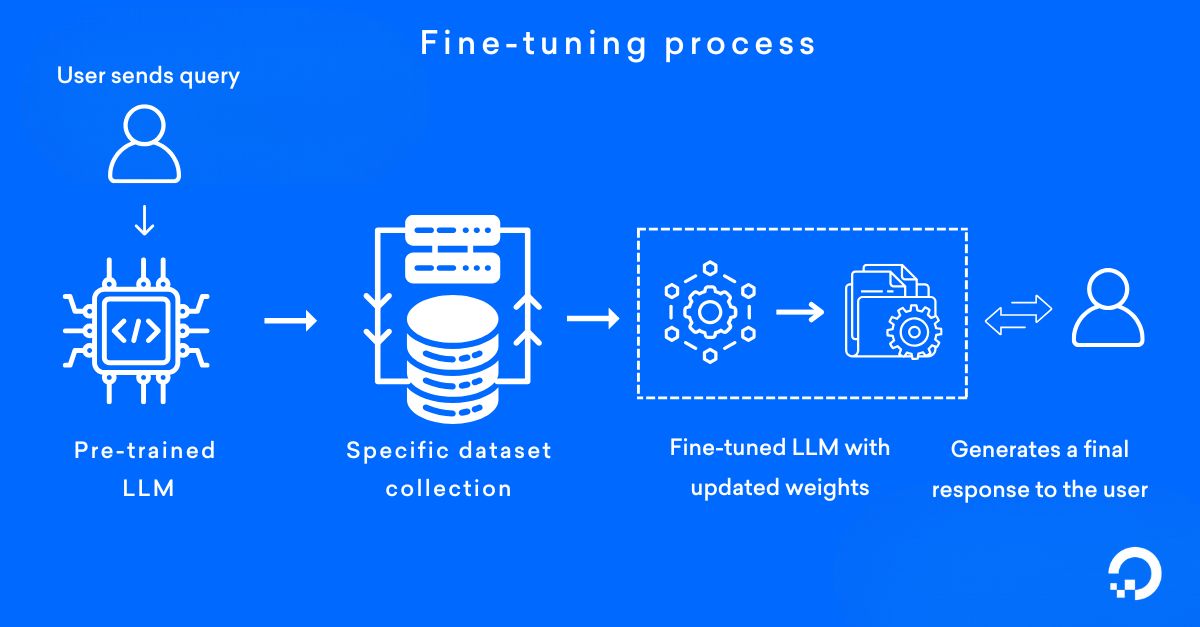
Begin by assessing the quality and volume of your proprietary data. Fine-tuning amplifies existing biases; without clean, structured datasets, the model will replicate errors at scale. Prioritize high-signal data that reflects specific enterprise contexts and compliance requirements.
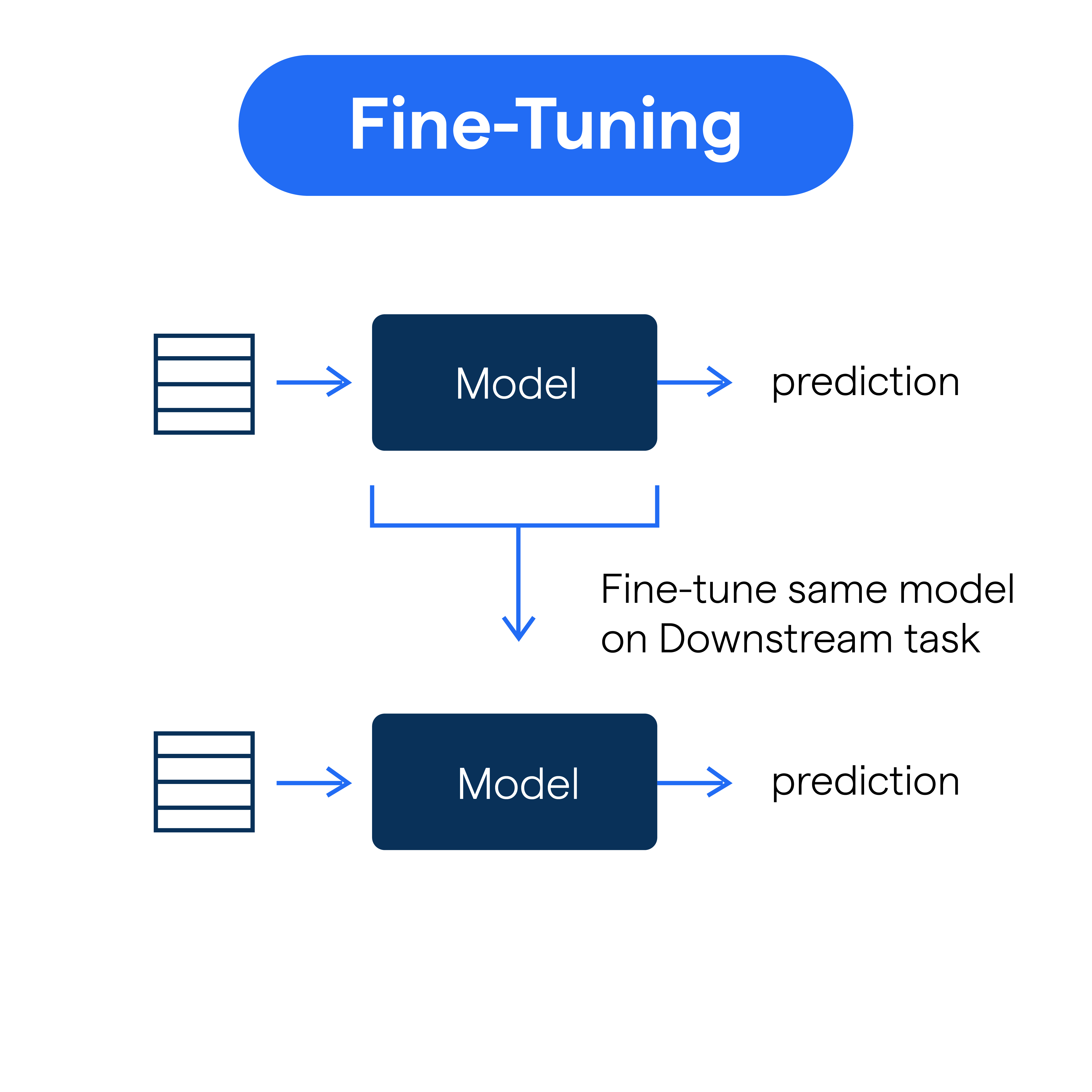
Choose between full parameter fine-tuning and efficient methods like LoRA. For most enterprise use cases in 2026, parameter-efficient fine-tuning offers the best balance of performance and cost. Evaluate the trade-off between computational overhead and marginal accuracy gains.
Implement continuous monitoring for drift and performance degradation. Fine-tuned models require ongoing validation against real-world inputs. Establish clear KPIs for latency, accuracy, and cost-per-token to ensure the solution remains economically viable over time.


As an Amazon Associate, we may earn from qualifying purchases.
The market for AI infrastructure continues to expand, driven by the need for specialized compute. Monitoring hardware costs and availability is essential for planning long-term fine-tuning operations. The chart above reflects recent trends in the underlying technology sector.
Hardware and software for fine-tuning
The infrastructure required for AI fine-tuning 2026 has shifted toward accessible, cloud-native workflows. You no longer need a dedicated server room to train a 7B parameter model. Current market data indicates that fine-tuning a 7B model now costs under $5, a dramatic reduction from previous years that lowers the barrier to entry for enterprise teams.
Selecting the right tools depends on your team’s technical depth. For organizations seeking a managed environment, Together AI offers a developer-friendly platform with broad model selection. However, many enterprises still prefer granular control over their hardware resources. The following tools and hardware configurations represent the standard stack for building a robust fine-tuning pipeline.



As an Amazon Associate, we may earn from qualifying purchases.
While hardware remains critical, the software layer dictates efficiency. Managed platforms reduce operational overhead, allowing data scientists to focus on prompt engineering and data quality rather than infrastructure maintenance. This shift enables faster iteration cycles and more precise model alignment for specific business use cases.
No comments yet. Be the first to share your thoughts!