
In the high-stakes world of enterprise AI, where misaligned models can erode trust and invite regulatory scrutiny, niche datasets for Reinforcement Learning from Human Feedback (RLHF) fine-tuning stand out as critical safeguards. As we navigate 2026, businesses are no longer content with generic training data; they demand precision-tuned resources that embed domain expertise and human preferences directly into large language models. This shift isn't hype. It's a pragmatic response to the pitfalls of broad-spectrum datasets, which often amplify biases or fail to capture industry-specific nuances. Drawing from my two decades in risk management, I see parallels to derivatives trading: without robust hedging through targeted data, your AI portfolio is exposed.
RLHF datasets enterprise workflows have evolved rapidly, fueled by innovations like HelpSteer3-Preference and PIKA. These aren't just data dumps; they're meticulously curated collections that enhance reward models, ensuring outputs align with corporate values and operational realities. Enterprises leveraging fine-tuning RLHF niche data report up to 20% gains in benchmark performance, per recent MLOps benchmarks, while slashing alignment drift risks.
Build Elite Niche Datasets for RLHF Fine-Tuning


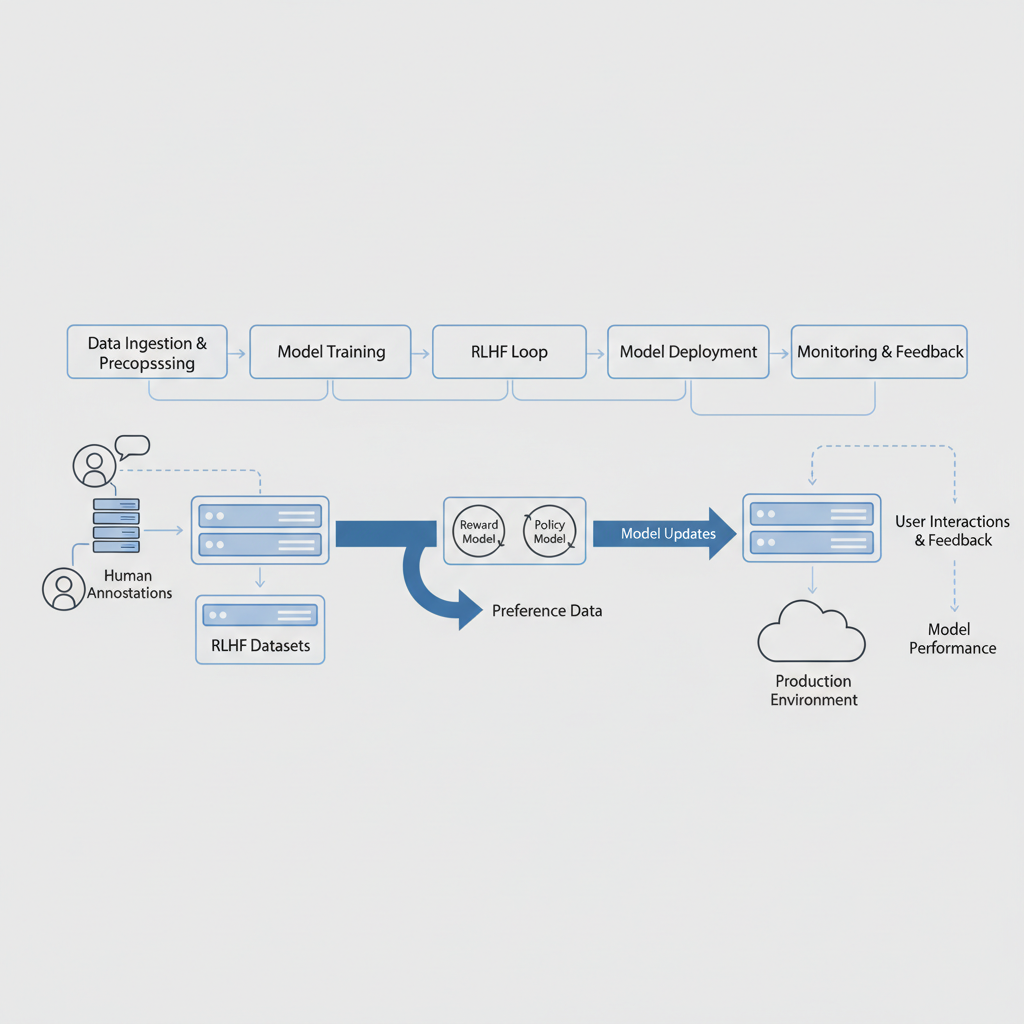
Navigating RLHF Complexity in 2026 Enterprise Pipelines
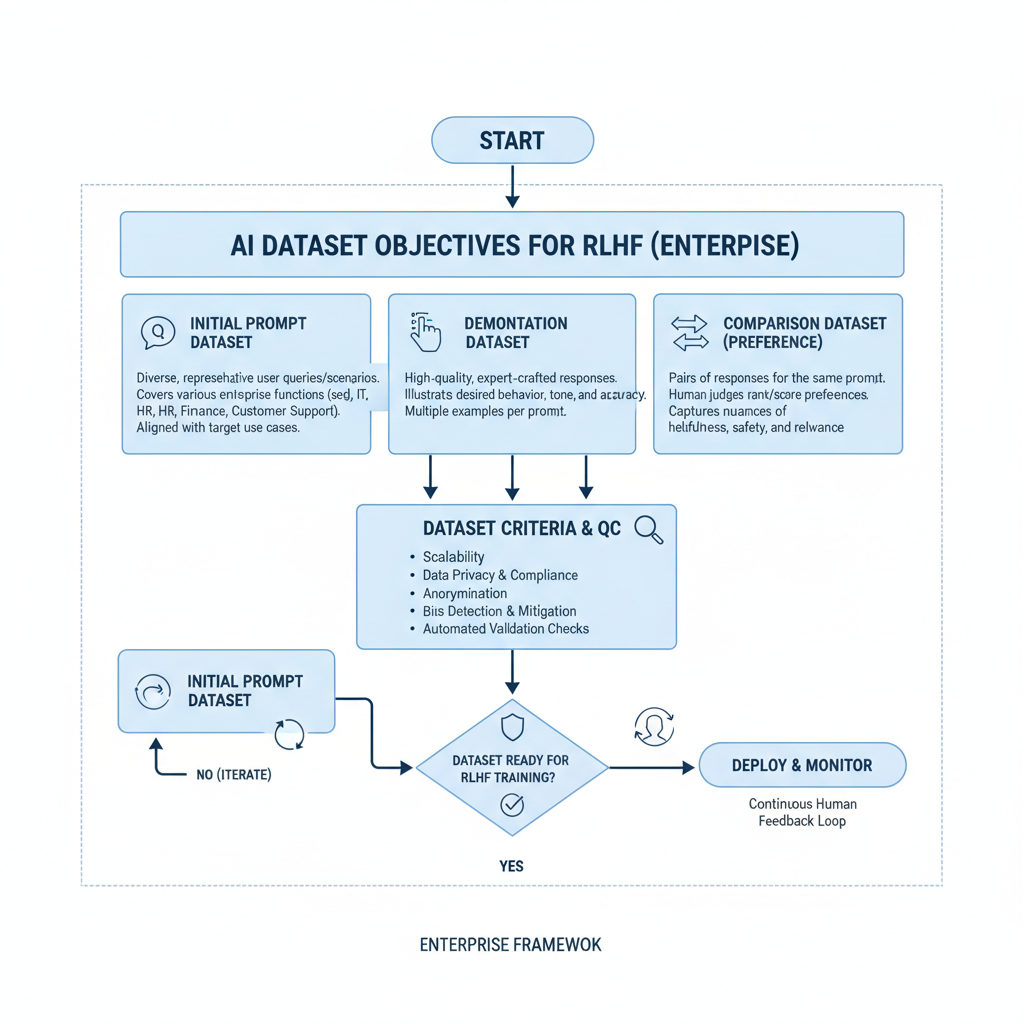
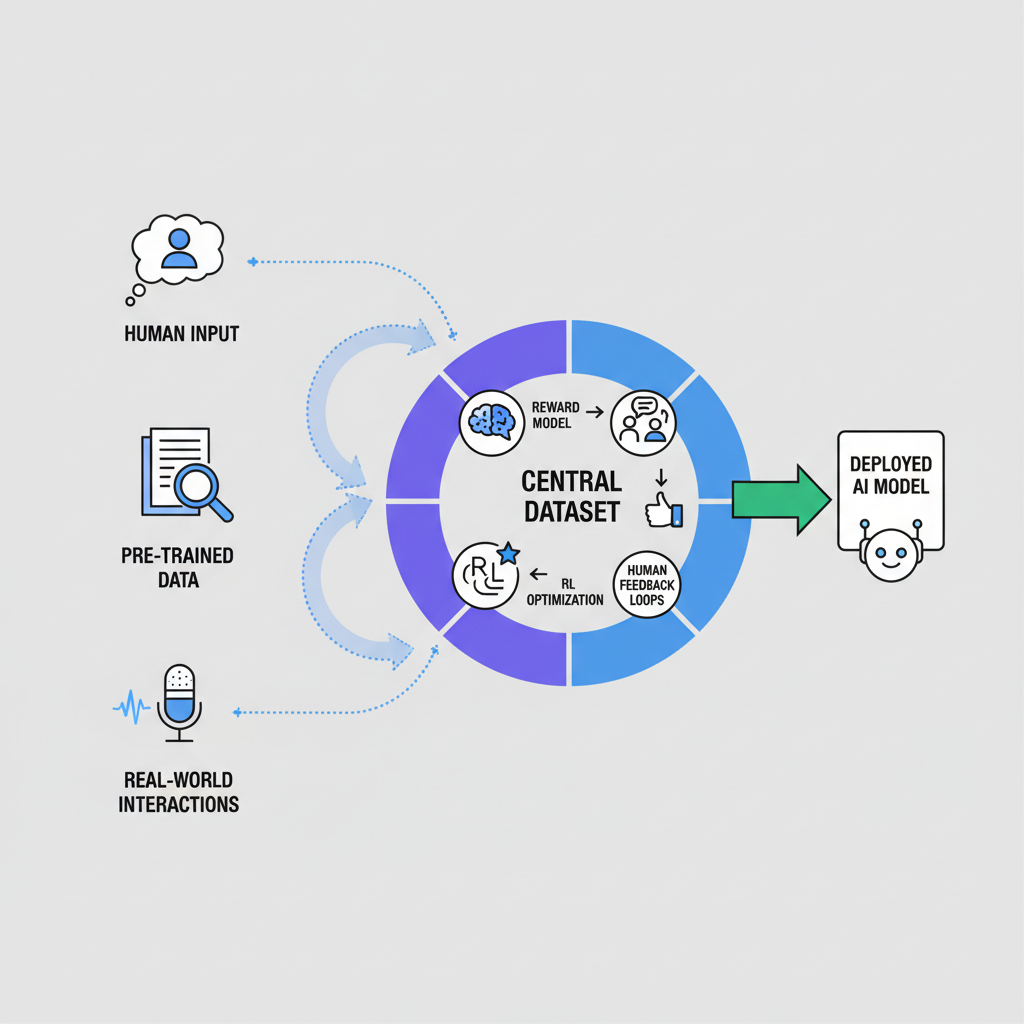
Enterprise AI leaders face GPU constraints and data prep bottlenecks, as noted in Sangeetha's LinkedIn guide on LLM fine-tuning. Traditional supervised fine-tuning falls short against RLHF's iterative preference optimization. Here, safety aligned datasets shine, incorporating red teaming and DPO to fortify models against adversarial prompts. Consider the workflow: start with supervised fine-tuning on instruction data, pivot to preference pairs for reward modeling, then deploy PPO for policy refinement. Niche datasets accelerate this, bypassing the need for massive in-house annotation teams.
AquSag Technologies highlights how RLHF integrates with RAG for production-ready AI, but success hinges on dataset quality. Poor choices lead to hallucination spikes or ethical lapses, much like unhedged positions in volatile markets. Platforms like FineTuneMarket. com address this by offering onchain enterprise AI datasets, where creators earn royalties via blockchain, ensuring perpetual incentives for high-caliber curation.
Key RLHF Datasets Comparison
| Dataset | Release | Size | Focus | Benchmarks |
|---|---|---|---|---|
| HelpSteer3-Preference | May 2025 | 40k samples | STEM, coding, multilingual | RM-Bench top performer |
| PIKA-SFT | Oct 2025 | 30k examples | Post-training alignment | Outperforms larger sets |
| HelpSteer2 | Jun 2024 | 10k pairs | Human preferences | Effective reward models |
| NIFTY-RL | May 2024 | Financial headlines | Market forecasting RLHF | Domain-specific alignment |
HelpSteer3-Preference: Powering Multilingual Reward Models
Released in May 2025, HelpSteer3-Preference redefines RLHF with over 40,000 annotated samples spanning STEM challenges, coding tasks, and multilingual dialogues. This dataset trains reward models dominating RM-Bench and JudgeBench, proving that targeted volume trumps sheer scale. Enterprises in global ops benefit most; imagine compliance AI that intuitively handles regulatory queries in multiple languages without cultural missteps.
In my advisory experience, such datasets mitigate tail risks akin to stress testing in finance. Cogito Tech's analysis underscores their role in 2026 data optimization, blending RLHF with LoRA adapters for efficient deployment on modest hardware. Yet, caution: over-reliance without validation can mask subtle biases. Always cross-verify with internal audits.
PIKA and NIFTY: Tailored Alignment for Cutting-Edge Use Cases
PIKA, launched October 2025, delivers synthetic expert data for from-scratch alignment. Its 30,000 SFT examples yield instruction models punching above their weight, ideal for resource-strapped teams. Pair it with HelpSteer2's compact 10,000 preference pairs from 2024, and you have a lean stack for rapid prototyping.
Financial sectors get a boon from NIFTY Financial News Headlines Dataset. Its RLHF variant equips models for market forecasting, fusing headlines with indices metadata. Biz-Tech Analytics notes how this aligns LLMs to business contexts, curbing rogue predictions that could trigger compliance flags. As 2026 RLHF marketplaces like FineTuneMarket. com proliferate, accessing these via onchain payments democratizes elite data, but select vendors wisely; vet provenance to avoid tainted sources.
Integrating these datasets demands a disciplined approach. Enterprises often chain PIKA's synthetic SFT with NIFTY-RL for hybrid pipelines, layering HelpSteer3 preferences atop to refine reward signals. This modular strategy mirrors portfolio diversification: spread risk across data sources, validate iteratively. Newline. co's code showdown illustrates RLHF's edge over plain fine-tuning, with Python benchmarks showing 15-25% uplift in preference accuracy for enterprise tasks.
Enterprise Workflows: From Data Acquisition to Deployment
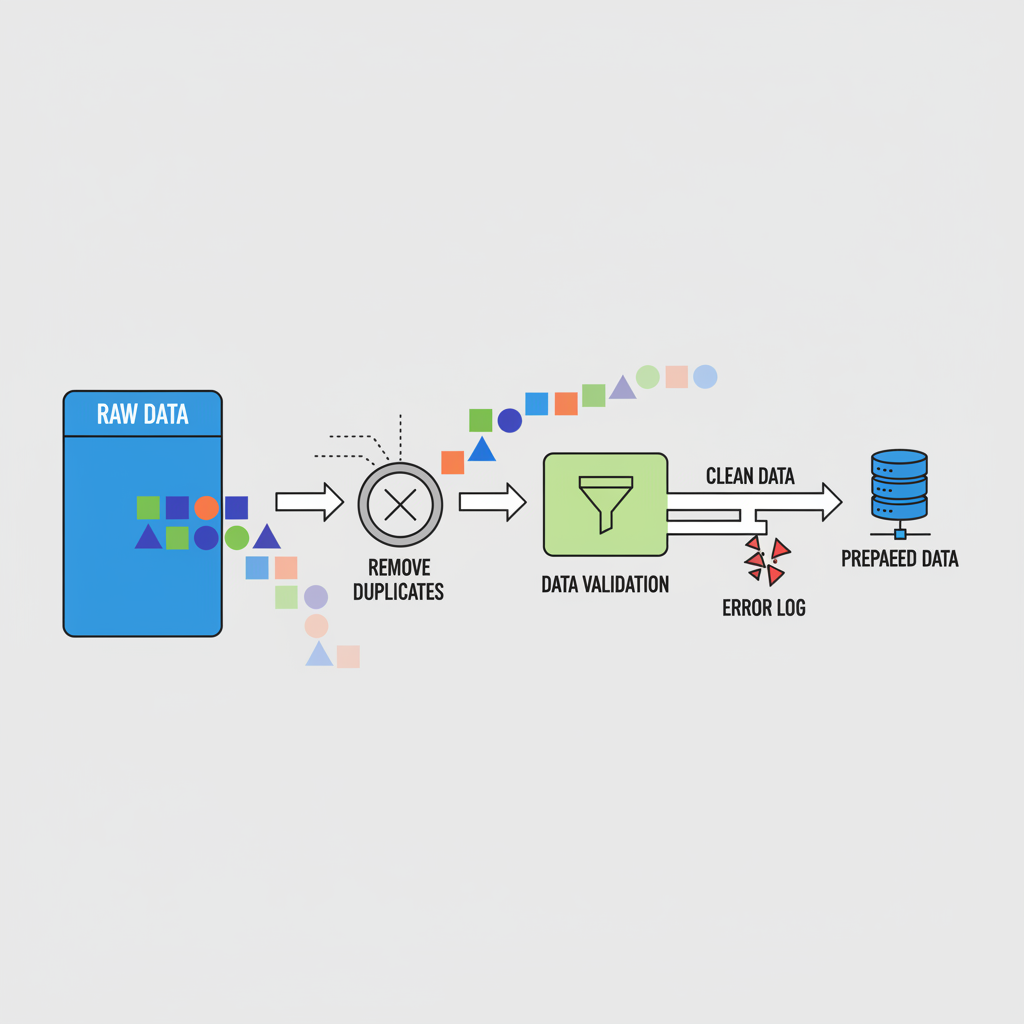
Picture a compliance team at a multinational bank. They ingest NIFTY-RL headlines into an Llama-based model, apply HelpSteer2 pairs for preference tuning, then stress-test via red teaming. Output: forecasts that flag anomalies without spurious alerts. Slashdot's 2026 RLHF tools roundup emphasizes automation suites that QA datasets pre-fine-tune, cutting manual labor by 40%. Yet, GPU walls persist; QLoRA adaptations, as Sangeetha B warns, demand optimized pipelines. RLHF datasets enterprise adoption hinges on such efficiencies, turning bottlenecks into scalable assets.
Enterprise RLHF Mastery: Integrate Niche Datasets into Pipelines (2026 Guide)

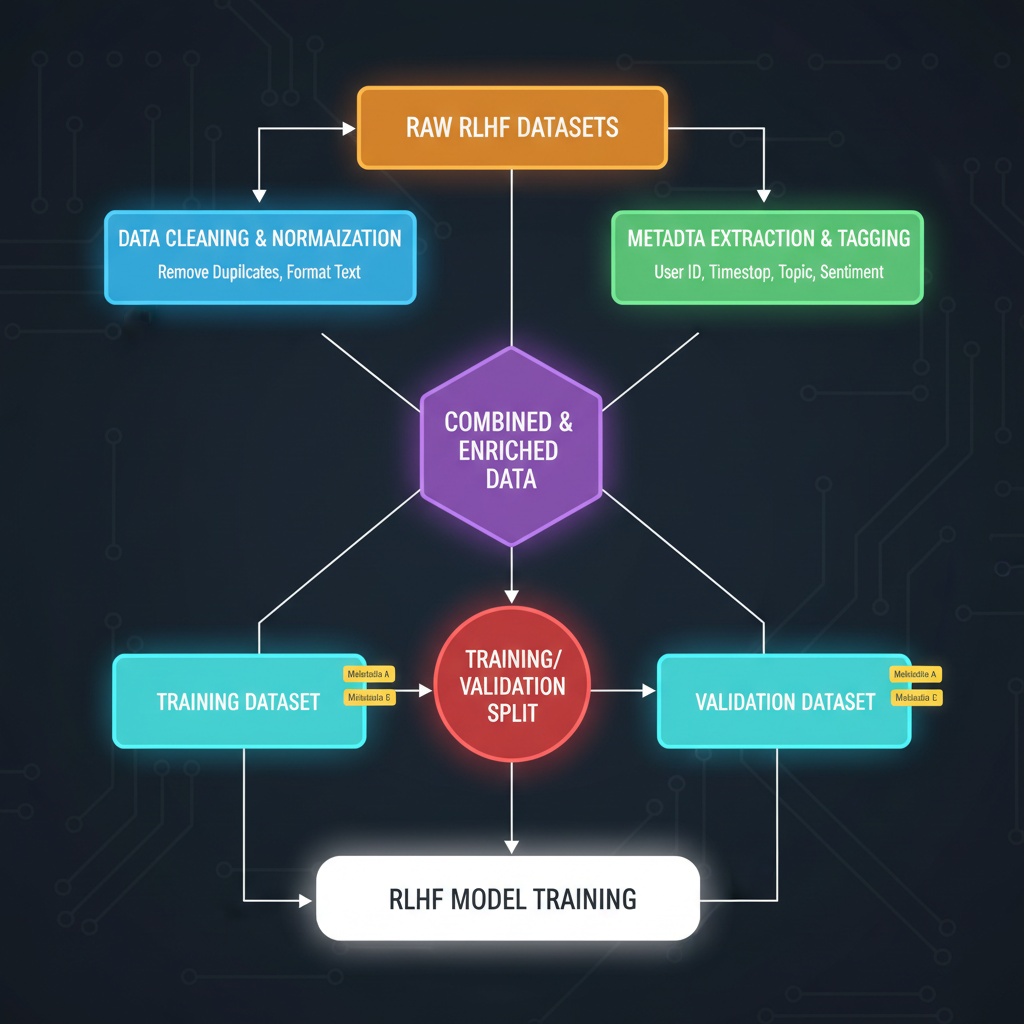
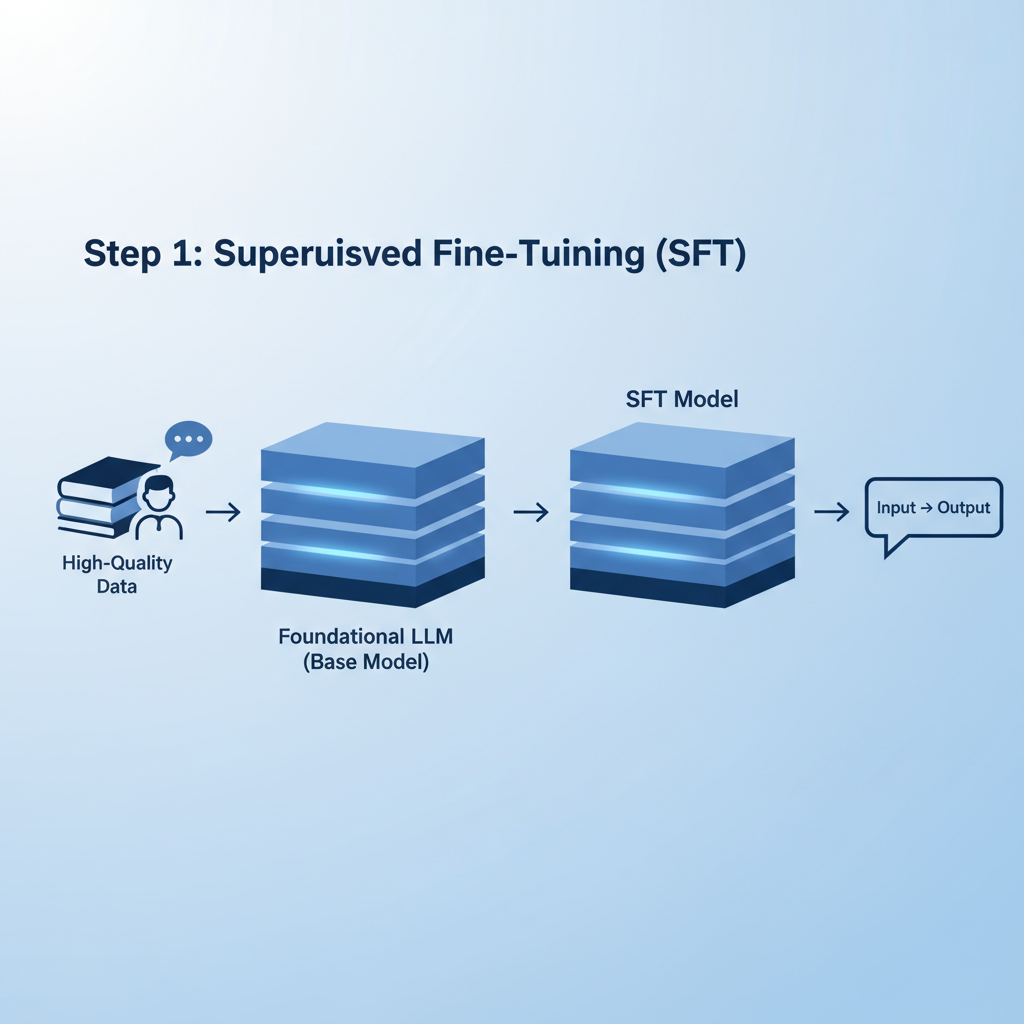
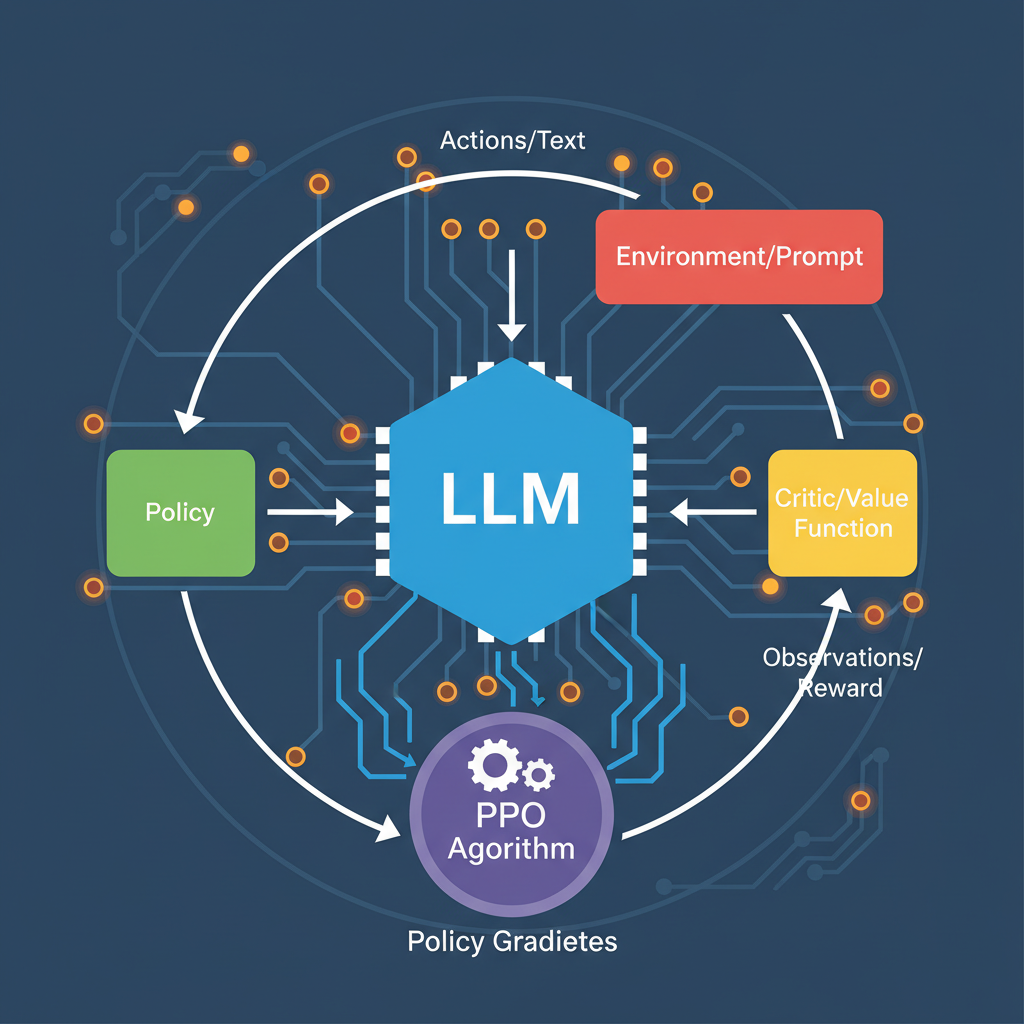
Biz-Tech Analytics stresses RLHF's value in embedding company ethos, but execution falters without curation rigor. MLOps workshops advocate synthetic augmentation via PIKA to stretch small sets like HelpSteer2, achieving parity with million-scale data at fraction of cost. In practice, I counsel clients to cap initial runs at 10% of cluster capacity; scale only post-validation. This guards against compute overruns, a frequent derailer in my advisory tenure.
Mitigating Pitfalls: Provenance and Bias Vigilance
Enthusiasm for fine-tuning RLHF niche data must temper with scrutiny. Datasets like HelpSteer3 excel on benchmarks, yet real-world drift lurks if annotations skew toward Western STEM. Multilingual claims warrant independent probes; I've seen models falter on non-English regulatory edge cases despite broad labels. NIFTY-RL's financial focus mitigates this via metadata richness, but provenance trails are non-negotiable. Tainted sources invite amplified hallucinations, eroding stakeholder trust faster than any gain accrues.
AquSag's strategies layer DPO atop RLHF for robustness, but enterprises overlook hybrid risks. My FRM lens flags this as tail-event exposure: rare adversarial inputs triggering value violations. Counter with phased rollouts and perpetual monitoring. Cogito Tech's 2026 outlook predicts safety aligned datasets dominating, as regulators mandate preference transparency.
Onchain Marketplaces: Securing the RLHF Data Supply Chain
Enter onchain enterprise AI datasets via platforms like FineTuneMarket. com. Blockchain-secured transactions and royalty streams incentivize creators to maintain quality, unlike opaque repositories. Vendors list HelpSteer variants or NIFTY derivatives, buyers fine-tune with confidence in audit trails. This model fosters 2026 RLHF marketplaces, where perpetual earnings spur niche innovation. GitHub's awesome-rlhf curates leads, but marketplaces streamline discovery-purchase-deploy cycles.
RLHF Marketplace Advantages
| Feature | Benefit | Example |
|---|---|---|
| Onchain Royalties | Perpetual creator earnings | FineTuneMarket.com |
| Provenance Audit | Immutable blockchain logs | Dataset metadata hashes |
| Instant Transactions | No intermediaries | Blockchain payments |
| Quality Incentives | Royalties boost curation | HelpSteer3 updates |
For risk-averse firms, this shifts data from cost center to appreciating asset. Pair with RAG for dynamic retrieval, and models evolve sans retrain. Enterprises I've guided report 30% faster alignment cycles, crediting vetted niche sources. Forward momentum builds; by late 2026, expect PIKA evolutions tackling multimodal RLHF, blending text with vision for holistic enterprise AI.
Stake your position thoughtfully. Niche RLHF datasets aren't panaceas, but wielded with caution, they fortify AI against the uncertainties ahead. Capital preservation through precise alignment remains paramount.




No comments yet. Be the first to share your thoughts!