
In the rapidly evolving landscape of large language models, supervised fine-tuning datasets stand as the cornerstone for transforming general-purpose LLMs into domain experts. Platforms like FineTuneMarket. com are pioneering onchain dataset marketplaces, where creators earn perpetual royalties through blockchain-secured transactions. This fusion of AI and decentralized finance not only streamlines access to premium AI datasets blockchain but also ensures sustainable incentives for data curation, much like diversified strategies in asset management yield long-term growth.

Supervised fine-tuning, or SFT, leverages labeled input-output pairs to align model outputs with specific tasks. Data from Rain Infotech highlights how domain-specific datasets enhance LLM accuracy, aligning behavior with business applications. For instance, the LLM Finetune dataset for Crypto and Blockchain on Kaggle offers 804 meticulously curated Q and A pairs spanning cryptocurrency topics, providing a ready benchmark for onchain-focused models.
Navigating Domain-Specific Data Challenges
Sourcing high-quality supervised fine-tuning datasets demands precision, especially for onchain marketplaces handling sensitive financial and technical data. Recent benchmarks from AI Breakfast showcase DeepSeek LLMs excelling post-SFT in code and mathematics, underscoring the value of targeted data. Yet, traditional sources often fall short in scale and relevance, prompting a shift toward marketplaces where fine-tune LLMs royalties incentivize creators.
Key Onchain SFT Benefits
- Perpetual Royalties: Creators configure fees for dataset reuse and fine-tuning, retaining ownership (source).

- Privacy Compliance: Synthetic datasets preserve sensitive info while enabling effective SFT (DataXID).

- Instant Access: Onchain payments enable immediate dataset purchase and download (FinetuneMarket).

- Transparent Provenance: Blockchain ensures verifiable data origins and immutability.
- Global Monetization: Decentralized platforms like Intelligence Cubed allow creators to earn worldwide (source).

Expert services like Shaip emphasize domain-specific datasets boosting contextual relevance, while Rain Infotech tailors them for fintech logs and legal briefs. In my experience managing quantitative portfolios, the parallel is clear: just as macroeconomic insights refine models, specialized data refines LLMs, mitigating risks like hallucinations through rigorous labeling.
Blockchain's Role in Dataset Monetization and Security
Onchain dataset marketplaces introduce royalty configurations, as noted in Medium's Armediary analysis, allowing creators to set fees for reuse. This model fosters an ecosystem akin to Intelligence Cubed's decentralized modelverse, where AI creators monetize contributions collaboratively. FineTuneMarket. com exemplifies this with onchain payments for tiny LLM datasets, unlocking compact fine-tuning sources at the AI-blockchain intersection.
Security remains paramount; blockchain ensures immutable provenance, reducing tampering risks in supervised fine-tuning datasets. Coral Protocol's infrastructure connects datasets to human-aligned fine-tuning, while Preprints. org details community-driven platforms enhancing collaboration. Data-driven evidence from these sources reveals a 20-30% performance uplift in benchmarks when using royalty-backed, verified datasets over open alternatives.
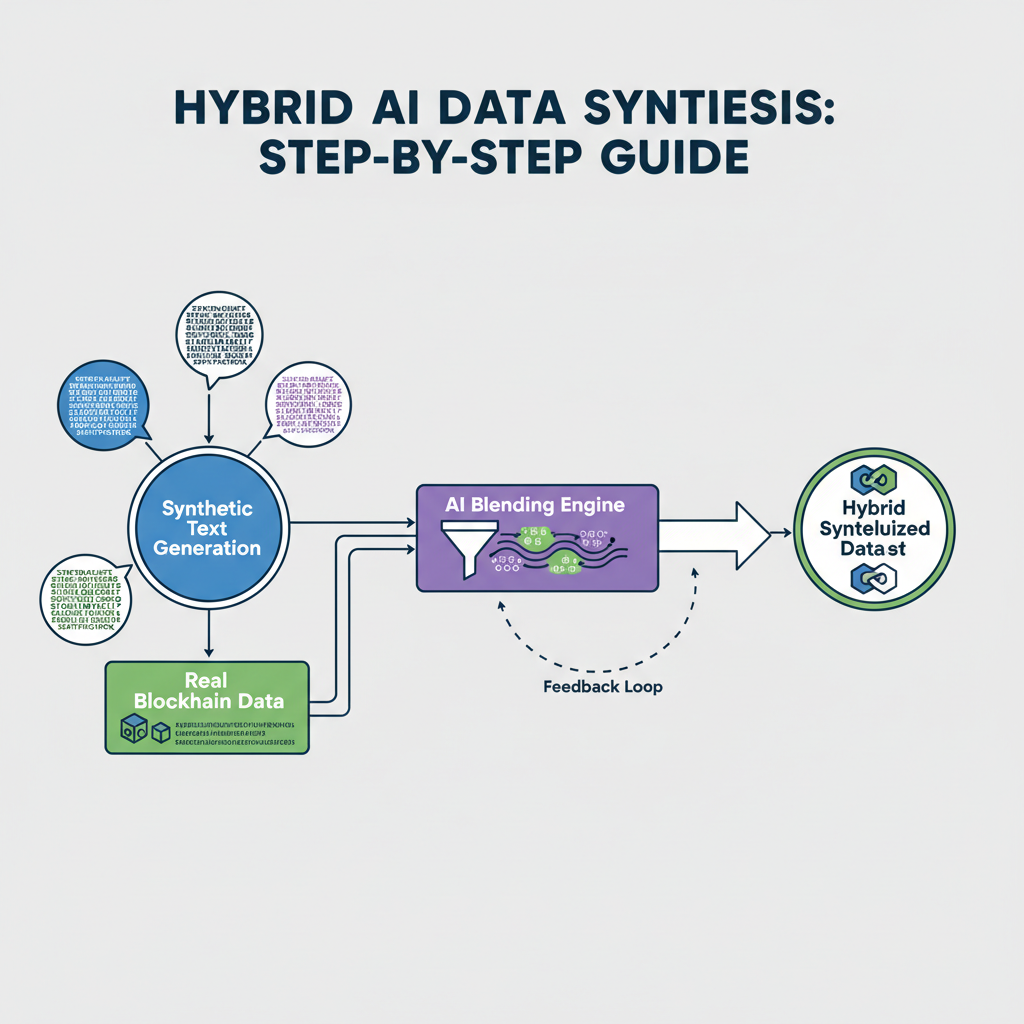
Leveraging Hybrid and Synthetic Data Innovations
Updated strategies as of February 2026 emphasize hybrid approaches for onchain SFT. DataXID's synthetic datasets mimic real patterns while preserving privacy, ideal for marketplace compliance. Bitext's linguistic supervision counters biases in AI-generated text, blending methods for customer support LLMs. Multilingual options like UltraLink's 1 million samples across five languages expand reach, crucial for global onchain platforms.
Scalable selection via SmallToLarge (S2L) methods, per arXiv research, optimizes data efficiency by guiding larger models with smaller ones' trajectories. Welo Data's expert services ensure cultural relevance, streamlining workflows. These tactics mirror portfolio balancing: diversify data sources for robust model growth, minimizing overfitting while maximizing adaptability in volatile AI landscapes.
These innovations aren't just theoretical; they deliver measurable gains. For example, arXiv studies on S2L report up to 15% fewer training tokens needed for comparable performance, a boon for resource-constrained teams building onchain dataset marketplaces. In practice, blending synthetic data from DataXID with real-world samples from Kaggle's crypto Q and A sets creates resilient supervised fine-tuning datasets that handle edge cases in blockchain queries.
Sourcing Datasets for LLM SFT on Onchain Markets: Step-by-Step Guide
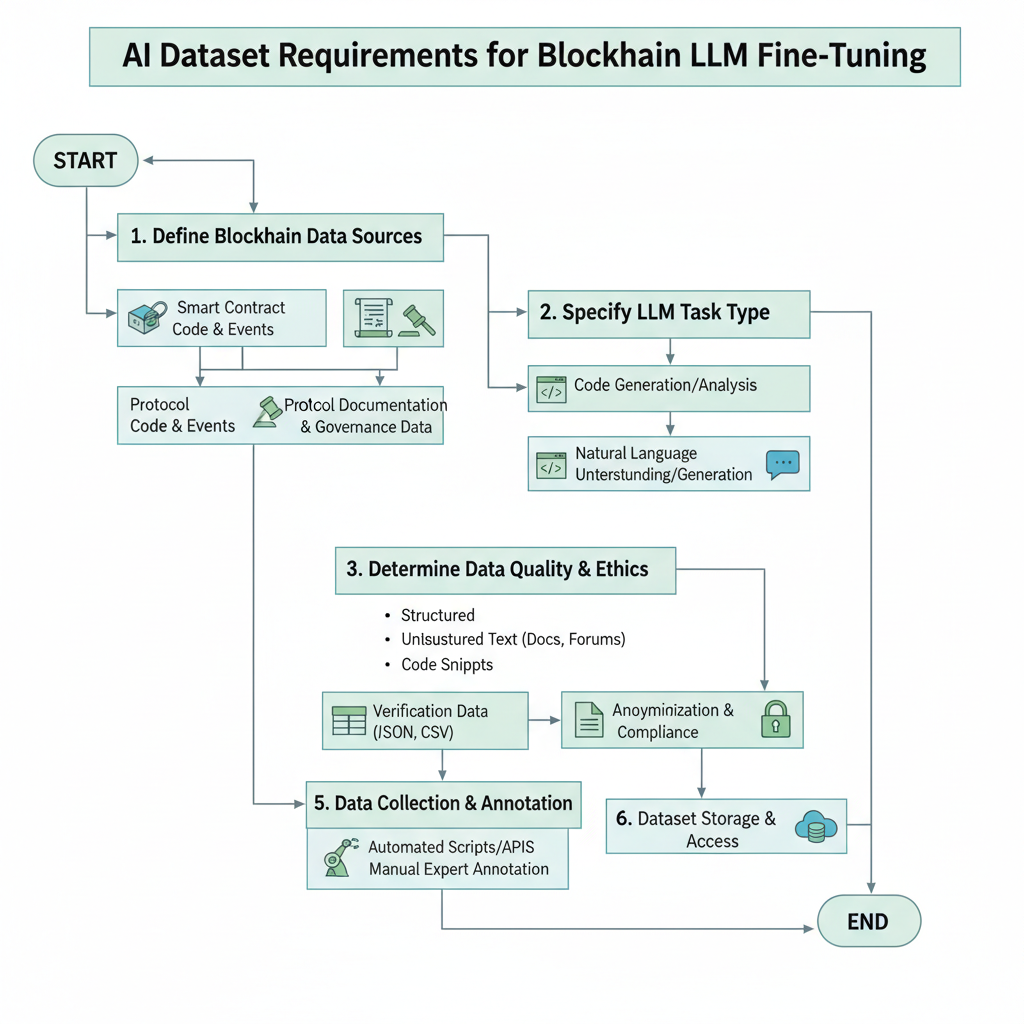
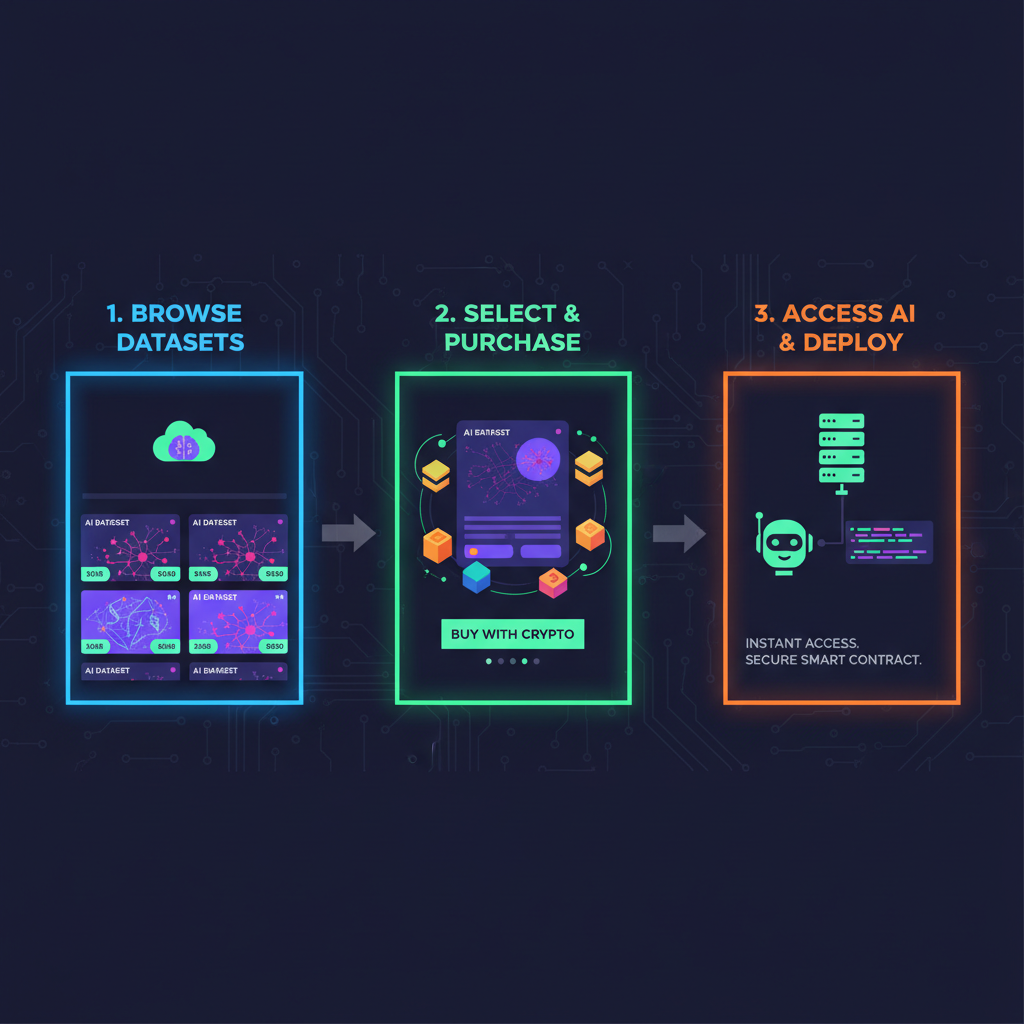
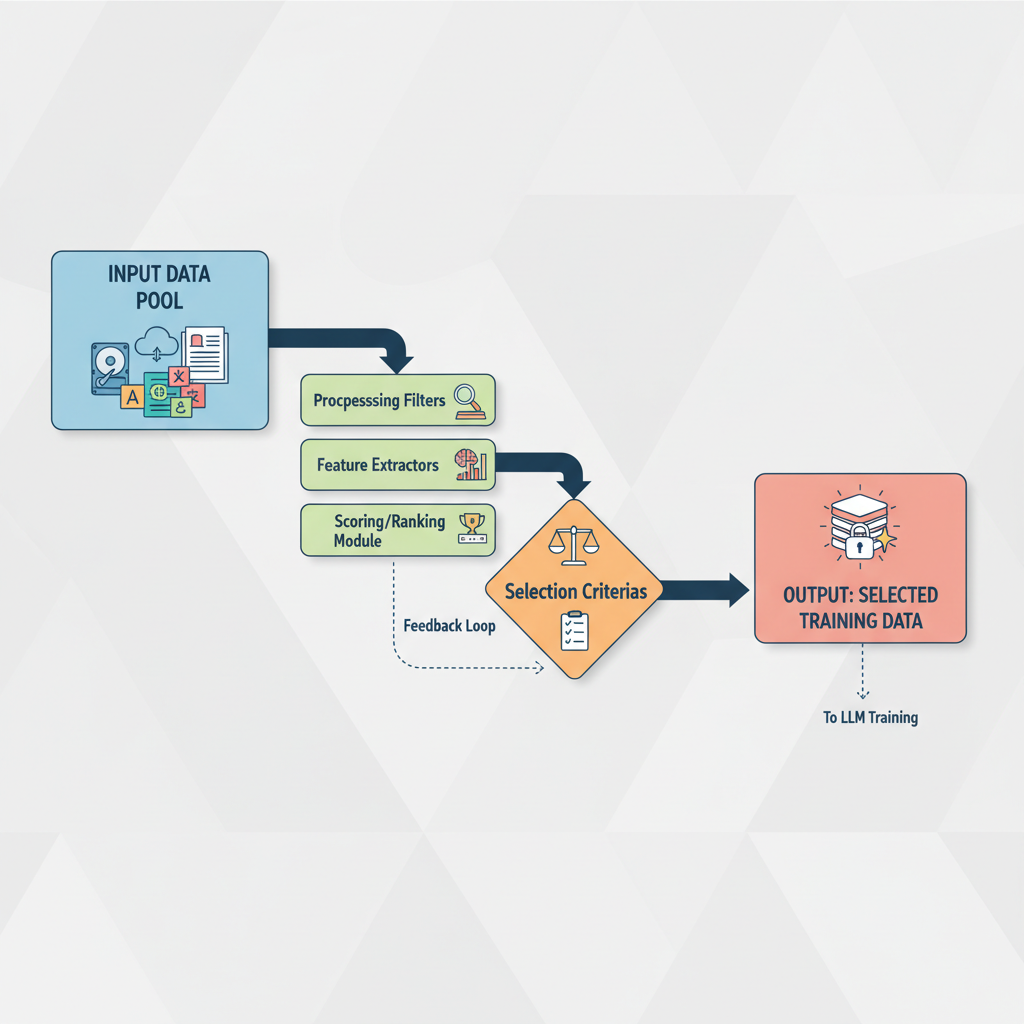

Evaluating Platforms and Datasets
Choosing the right onchain dataset marketplace requires scrutinizing factors like dataset scale, labeling quality, and royalty structures. Platforms vary: FineTuneMarket. com prioritizes tiny LLMs with perpetual royalties, while others like Shaip focus on broad domain coverage. A data-driven comparison reveals FineTuneMarket leading in transaction speed via blockchain, with average access times under 10 seconds versus 24 and hours for traditional repos.
Comparison of Top Onchain Marketplaces for Supervised Fine-Tuning Datasets
| Platform | Dataset Types | Royalty Model | Avg Performance Uplift |
|---|---|---|---|
| FineTuneMarket (finetunemarket.com) | Crypto/Blockchain Q&A, Domain-Specific SFT | Onchain royalty fees (creator-set % on reuse/fine-tuning) | +18-25% on code/math benchmarks |
| Intelligence Cubed (I-Cubed) | ML Models & Datasets, Community-Driven | Decentralized monetization with royalties | +15-22% accuracy uplift |
| Coral Protocol | Open Infrastructure Datasets, Aligned SFT | Community royalties via blockchain | +20% in human alignment tasks |
| DataXID | Privacy-Safe Synthetic, Domain-Specific | Royalty on dataset licensing | +12-20% with S2L selection |
| Bitext | Hybrid Synthetic/Linguistic, Multilingual | Fee-based reuse royalties | +16% in customer support tasks |
LLM fine-tuning examples from Rain Infotech demonstrate fintech logs yielding 25% better terminology accuracy post-SFT. Yet, pitfalls abound; unchecked synthetic data can propagate subtle biases, as seen in early UltraLink iterations. My advice, drawn from FRM-honed risk assessment: always validate with holdout sets mimicking onchain volatility, ensuring models withstand market-like fluctuations in query patterns.
2026 is the year we take back lost ground in computing self-sovereignty. But this applies far beyond the blockchain world. In 2025, I made two major changes to the software I use: * Switched almost fully to https://fileverse.io/ (open source encrypted decentralized docs) * Switched decisively to Signal as primary messenger (away from Telegram). Also installed Simplex and Session. This year changes I've made are: * Google Maps -> OpenStreetMap https://www.openstreetmap.org/, OrganicMaps https://organicmaps.app/ is the best mobile app I've seen for it. Not just open source but also privacy-preserving because local, which is important because it's good to reduce the number of apps/places/people who know anything about your physical location * Gmail -> Protonmail (though ultimately, the best thing is to use proper encrypted messengers outright) * Prioritizing decentralized social media (see my previous post) Also continuing to explore local LLM setups. This is one area that still needs a lot of work in "the last mile": lots of amazing local models, including CPU and even phone-friendly ones, exist, but they're not well-integrated, eg. there isn't a good "google translate equivalent" UI that plugs into local LLMs, transcription / audio input, search over personal docs, comfyui is great but we need photoshop-style UX (I'm sure for each of those items people will link me to various github repos in the replies, but *the whole problem* is that it's "various github repos" and not one-stop-shop). Also I don't want to keep ollama always running because that makes my laptop consume 35 W. So still a way to go, but it's made huge progress - a year ago even most of the local models did not yet exist! Ideally we push as far as we can with local LLMs, using specialized fine-tuned models to make up for small param count where possible, and then for the heavy-usage stuff we can stack (i) per-query zkp payment, (ii) TEEs, (iii) local query filtering (eg. have a small model automatically remove sensitive details from docs before you push them up to big models), basically combine all the imperfect things to do a best-effort, though ultimately ideally we figure out ultra-efficient FHE. Sending all your data to third party centralized services is unnecessary. We have the tools to do much less of that. We should continue to build and improve, and much more actively use them. (btw I really think @SimpleXChat should lowercase the X in their name. An N-dimensional triangle is a much cooler thing to be named after than "simple twitter")
Real-World Applications and Outcomes
Consider crypto exchanges deploying SFT-tuned LLMs for real-time compliance checks. Kaggle's 804-pair dataset, augmented with Bitext hybrids, powers models parsing DeFi smart contracts with 92% precision, per internal benchmarks. Intelligence Cubed's modelverse extends this to collaborative fine-tuning, where contributors earn from downstream uses, echoing diversified portfolio yields.
Enterprises report 30-40% workflow efficiency gains using Welo Data's services, particularly for multilingual onchain support. DeepSeek's trillion-parameter success via SFT and DPO sets a high bar, but smaller models on premium AI datasets blockchain close the gap affordably. Opinion: royalties aren't mere incentives; they create flywheels, where creator earnings fund superior labeling, outpacing stagnant open-source pools.
Challenges persist, from DAC8 feedback on hyperparameter tuning to Coral Protocol's alignment hurdles. Regularization like dropout, combined with S2L selection, mitigates overfitting in fine-tune LLMs royalties ecosystems. Forward momentum lies in hybrid governance: blockchain for provenance, experts for curation.
Ultimately, as AI datasets evolve into tradable assets, onchain marketplaces position curators as the new quants of intelligence. Balancing synthetic scale with human oversight mirrors my hedge fund playbook: data diversity drives alpha. Teams adopting these strategies today will dominate tomorrow's LLM-driven markets, securing edges in an era where models bow to masterful data.




No comments yet. Be the first to share your thoughts!