
In the symphony of economic forces shaping our digital future, large language models (LLMs) hum a melody that's grown increasingly sophisticated, yet often discordant in tone. Imagine crafting transaction confirmations for onchain payments that read like a casual chat over coffee, not a robotic ledger entry. This isn't fantasy; it's the frontier where premium datasets for fine-tuning LLMs meet blockchain's unyielding transparency. FineTuneMarket. com stands at this nexus, orchestrating a marketplace where creators sell specialized datasets and reap perpetual royalties through onchain payments. As AI developers chase that elusive natural tone, the demand surges for fine-tuning datasets natural tone that imbue models with human nuance.
Unlocking Natural AI Eloquence: LLM Fine-Tuning Crash Course





The rhythm quickens with tools like Tuna from LangChain, which spins synthetic datasets from thin air, or Bitext's hybrid creations blending scale and curation. These aren't mere data dumps; they're symphonies tuned for conversational finesse, vital for onchain applications where trust hinges on relatable language. Picture a DeFi protocol explaining yield farming in prose that feels intuitive, not instructional. Yet, sourcing such gold-standard data remains a bottleneck, pushing innovators toward marketplaces that reward quality with blockchain-backed economics.
Unlocking Natural Tone Through Curated Datasets
At the heart of LLM evolution lies tone adjustment, a subtle art that generic pre-training overlooks. LLM tone adjustment datasets emerge as the conductors, guiding models from stiff formality to fluid authenticity. Take Nexdata's 2 million pairs of instruction-following text: 95% accuracy in diverse scenarios, primed for foundation models craving natural responses. Or DataXID's blockchain platform, generating synthetic data that dodges privacy pitfalls while honing domain-specific precision. These resources whisper the secrets of everyday dialogue, essential for onchain payments AI datasets where users demand clarity without jargon.
Premium Datasets for LLM Fine-Tuning
- Bitext Hybrid Synthetics: Expertly curated datasets blending synthetic scale with manual precision for natural conversational AI in customer support and beyond. Explore
- Nexdata 2M Pairs: 2 million high-accuracy (95%+) instruction-following Q&A pairs to elevate LLMs in generating fluid, natural responses. Discover

- DataXID Synthetic Platform: Blockchain-powered synthetic data for privacy-focused, domain-specific LLM tuning—ideal for onchain payment apps. View

- Amazon Bedrock Synthetics: Leverage teacher models to craft context-aware data, fine-tuning student LLMs for precise, natural Q&A in specialized domains. Read

- Tuna by LangChain: No-code tool for instant synthetic datasets—thousands of quality prompt-completion pairs via intuitive web or Python. Try Tuna
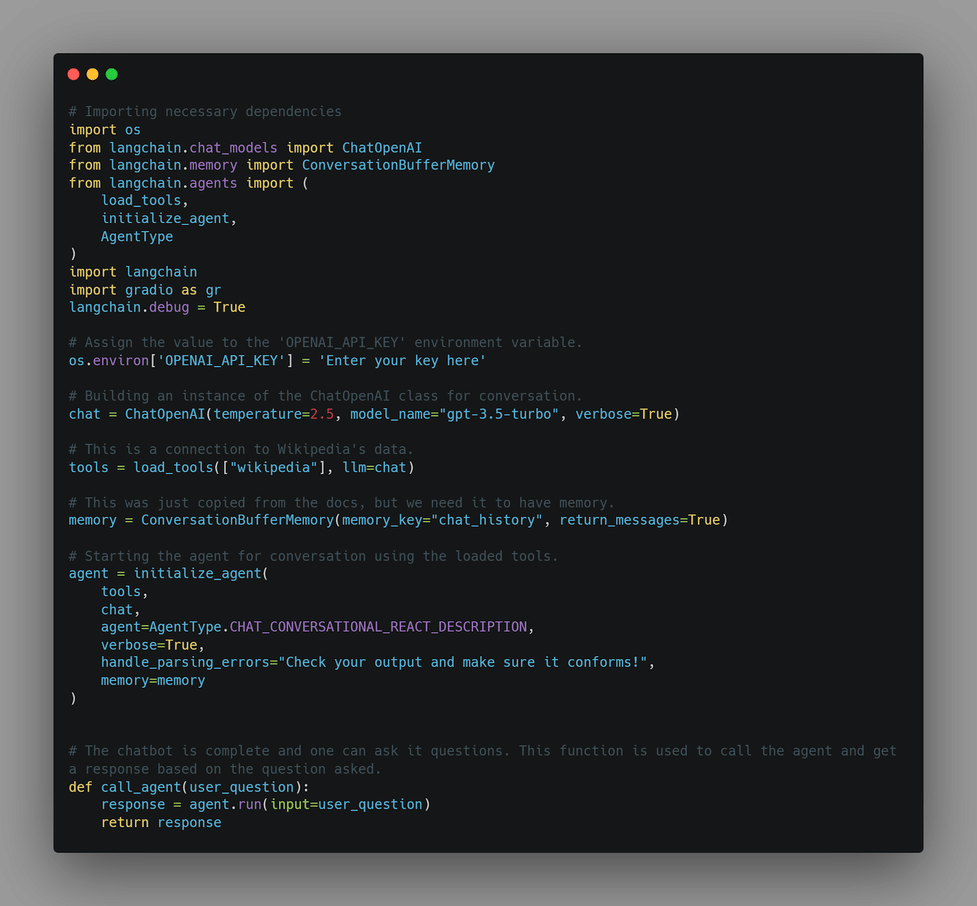
I've watched commodities supercycles unfold over 14 years, spotting patterns in scarcity and value. Datasets mirror this: high-quality ones command premiums because they amplify model performance exponentially. Amazon Bedrock's synthetic generation, leveraging teacher models for student fine-tuning, exemplifies efficiency. No longer do engineers toil over manual labeling; these tools democratize excellence, fostering ecosystems where natural tone becomes the default.
Blockchain Marketplaces as the New Data Symphony
Enter blockchain marketplace fine-tuning, where FineTuneMarket. com redefines discovery and monetization. Creators upload premium LLM training data, buyers fine-tune via seamless onchain payments, and royalties flow eternally. This isn't just transactional; it's a perpetual motion machine for innovation. Consider the bitcoin-llm-finetuning-dataset on Hugging Face, a harbinger of crypto-infused training data. Scaled to onchain narratives, such datasets train LLMs to narrate wallet movements with warmth, boosting user retention in Web3 apps.

Visionaries in machine learning echo this shift. Guides from arXiv and Medium detail LangChain integrations, while GitHub repos offer scripts for text-generation fine-tuning. Yet, the true game-changer is premium curation. Bitext's conversational datasets shine for customer support analogs in payments, ensuring LLMs respond with empathy. DataXID reduces bias, critical for equitable onchain interactions. As cycles turn bullish on AI, premium LLM training data royalties incentivize creators, mirroring bond yields in their compounding allure. Tuna's no-code interface lowers barriers, letting even solo devs craft thousands of prompt-completion pairs tailored to natural cadence.
Synthetic Mastery Meets Real-World Demands
Synthetic data isn't a shortcut; it's evolution accelerated. Tools like Tuna generate datasets rapidly, but premium hybrids elevate them. Nexdata's multilingual scope covers instruction-following vital for global onchain protocols. Pair this with PEFT techniques from LinkedIn guides, and smaller models punch above weight. The narrative arcs toward marketplaces where such assets trade frictionlessly, royalties etching value into the blockchain ledger. Developers fine-tune for context-based QA via Amazon Bedrock, yielding tones that resonate in DeFi dashboards or NFT marketplaces.
Imagine an LLM narrating a cross-chain swap not as cold code, but as a storyteller recounting a bridge between realms. This vividness stems from datasets like those in opendatascience's top 10, each infusing unique flavors into model palates. Yet, in the crescendo of onchain payments AI datasets, scarcity breeds value. FineTuneMarket. com captures this, turning ephemeral data into enduring assets via premium LLM training data royalties. Creators embed smart contracts that pulse royalties with every fine-tune, echoing the relentless tick of bond yields in a rising rate environment.
Orchestrating Royalties in the Data Cycle
Over my 14 years tracking global cycles, I've seen how scarcity ignites supercycles. Datasets for fine-tuning datasets natural tone follow suit: rare, high-fidelity ones spark AI's next boom. Blockchain marketplaces like FineTuneMarket. com conduct this orchestra, where onchain payments ensure instant, borderless trades. No middlemen siphoning value; instead, perpetual royalties reward foresight. A dataset tuned for natural DeFi explanations? It earns anew each time a protocol integrates it, compounding like commodities in a bull run.
How I think about "security": The goal is to minimize the divergence between the user's intent, and the actual behavior of the system. "User experience" can also be defined in this way. Thus, "user experience" and "security" are thus not separate fields. However, "security" focuses on tail risk situations (where downside of divergence is large), and specifically tail risk situations that come about as a result of adversarial behavior. One thing that becomes immediately obvious from the above definition, is that "perfect security" is impossible. Not because machines are "flawed", or even because humans designing the machines are "flawed", but because "the user's intent" is fundamentally an extremely complex object that the user themselves does not have easy access to. Suppose the user's intent is "I want to send 1 ETH to Bob". But "Bob" is itself a complicated meatspace entity that cannot be easily mathematically defined. You could "represent" Bob with some public key or hash, but then the possibility that the public key or hash is not actually Bob becomes part of the threat model. The possibility that there is a contentious hard fork, and so the question of which chain represents "ETH" is subjective. In reality, the user has a well-formed picture about these topics, which gets summarized by the umbrella term "common sense", but these things are not easily mathematically defined. Once you get into more complicated user goals - take, for example, the goal of "preserving the user's privacy" - it becomes even more complicated. Many people intuitively think that encrypting messages is enough, but the reality is that the metadata pattern of who talks to whom, and the timing pattern between messages, etc, can leak a huge amount of information. What is a "trivial" privacy loss, versus a "catastrophic" loss? If you're familiar with early Yudkowskian thinking about AI safety, and how simply specifying goals robustly is one of the hardest parts of the problem, you will recognize that this is the same problem. Now, what do "good security solutions" look like? This applies for: * Ethereum wallets * Operating systems * Formal verification of smart contracts or clients or any computer programs * Hardware * ... The fundamental constraint is: anything that the user can input into the system is fundamentally far too low-complexity to fully encode their intent. I would argue that the common trait of a good solution is: the user is specifying their intention in multiple, overlapping ways, and the system only acts when these specifications are aligned with each other. Examples: * Type systems in programming: the programmer first specifies *what the program does* (the code itself), but then also specifies *what "shape" each data structure has at every step of the computation*. If the two diverge, the program fails to compile. * Formal verification: the programmer specifies what the program does (the code itself), and then also specifies mathematical properties that the program satisfies * Transaction simulations: the user specifies first what action they want to take, and then clicks "OK" or "Cancel" after seeing a simulation of the onchain consequences of that action * Post-assertions in transactions: the transaction specifies both the action and its expected effects, and both have to match for the transaction to take effect * Multisig / social recovery: the user specifies multiple keys that represent their authority * Spending limits, new-address confirmations, etc: the user specifies first what action they want to take, and then, if that action is "unusual" or "high-risk" in some sense, the user has to re-specify "yes, I know I am doing something unusual / high-risk" In all cases, the pattern is the same: there is no perfection, there is only risk reduction through redundancy. And you want the different redundant specifications to "approach the user's intent" from different "angles": eg. action, and expected consequences, expected level of significance, economic bound on downside, etc This way of thinking also hints at the right way to use LLMs. LLMs done right are themselves a simulation of intent. A generic LLM is (among other things) like a "shadow" of the concept of human common sense. A user-fine-tuned LLM is like a "shadow" of that user themselves, and can identify in a more fine-grained way what is normal vs unusual. LLMs should under no circumstances be relied on as a sole determiner of intent. But they are one "angle" from which a user's intent can be approximated. It's an angle very different from traditional, explicit, ways of encoding intent, and that difference itself maximizes the likelihood that the redundancy will prove useful. One other corollary is that "security" does NOT mean "make the user do more clicks for everything". Rather, security should mean: it should be easy (if not automated) to do low-risk things, and hard to do dangerous things. Getting this balance right is the challenge.
Practical fusion happens daily. GitHub's llm-finetuning notebooks pair with DigitalOcean's data creation blueprints, but premium inputs elevate outputs. Hugging Face's bitcoin-llm-finetuning-dataset hints at crypto-specific tones, yet lacks the polish of curated premiums. Visionary devs blend these: synthetic from Tuna, refined via Bitext, deployed through LangChain steps from Medium guides. Result? LLMs that converse about gas fees with the ease of old friends, retention soaring in wallet apps and DEXes.
The Reddit r/LocalLLaMA curation underscores demand for general-purpose excellence, but onchain niches demand more. Krishna Chaitanya's PEFT walkthroughs transform unstructured chaos into structured gold, amplified by Nexdata's volume. DataXID's bias mitigation ensures fairness in global protocols, where tone missteps erode trust faster than a flash crash. Amazon Bedrock's QA synthetics bridge gaps, training compact models for edge devices in Web3 hardware.
Cycles Converge: AI, Blockchain, and Human Nuance
As economic forces harmonize, blockchain marketplace fine-tuning emerges dominant. FineTuneMarket. com isn't a store; it's a ledger of legacies, where datasets live beyond one sale. Krish Naik's crash course illuminates basics, but premiums unlock mastery. I've forecasted yields through volatility; similarly, bet on datasets fueling LLM's tone renaissance. Enterprises eye this for compliant, natural interfaces in tokenized assets. Researchers curate for arXiv-grade insights, engineers iterate via YouTube-proven flows.
Envision the horizon: LLMs as confidants in onchain economies, their voices woven from premium threads. Tools evolve, from no-code Tuna to hybrid Bitexts, but marketplaces eternalize them. Royalties incentivize a deluge of quality, scarcity yielding to abundance without dilution. In this symphony, natural tone isn't tuned; it's reborn, powering protocols where users linger, transact, thrive. FineTuneMarket. com leads the baton, inviting creators and builders to compose the next movement.




No comments yet. Be the first to share your thoughts!