
In 2026, fine-tuning large language models with reinforcement learning from human feedback demands datasets of unyielding quality, where a single lapse in annotation rigor can cascade into misaligned outputs and eroded trust. Onchain marketplaces have transformed this landscape, offering verifiable provenance and perpetual royalties for creators, yet sourcing requires a disciplined eye to mitigate risks inherent in data dependencies. Platforms like FineTuneMarket. com lead by curating premium RLHF datasets, blending blockchain security with AI-grade precision for developers wary of opaque supply chains.
RLHF's Core Reliance on Human Preference Data
Reinforcement learning from human feedback refines LLMs by distilling subjective human judgments into objective reward signals, a process Nathan Lambert terms the 'engine of preference fine-tuning. ' Unlike brute-force supervised learning, RLHF hinges on paired responses ranked by annotators, capturing nuances that synthetic data often misses. From arXiv papers to MLOps workshops, experts underscore that poor preference data inflates variance in reward models, leading to brittle alignments. My two decades in risk management echo this: treat datasets as derivatives, where hidden leverage in annotation bias amplifies downstream losses.
Consider the evolution from HelpSteer2's modest 10,000 pairs to HelpSteer3-Preference's expansive 40,000 samples across multilingual tasks. These aren't mere increments; they represent hardened defenses against overfitting, licensed permissively under CC-BY-4.0 for broad adoption. Yet, enthusiasm must temper with scrutiny, as even state-of-the-art benchmarks falter without diverse, vetted inputs.
Spotlight on Premium Datasets in Onchain Ecosystems
Onchain marketplaces democratize access to RLHF datasets, enforcing transparency via blockchain ledgers that trace every annotation back to its source. HelpSteer3-Preference, released May 2025, dominates with its scale and task diversity, powering reward models that outpace predecessors on leaderboards. PIKA, arriving October 2025, flips the script with synthetic efficiency, delivering alignment from fewer examples, ideal for resource-constrained teams. HelpSteer2 endures for its punchy efficacy, while NIFTY carves a niche in financial forecasting, merging headlines with metadata for domain-specific RLHF.
These assets thrive on platforms prioritizing data quality and scalability, but selection demands more than hype. iMerit's insights align data annotation with RLHF as symbiotic forces; neglect one, and the other crumbles. AWS tutorials affirm direct fine-tuning from preference pairs, yet warn of garbage-in-garbage-out pitfalls absent rigorous curation.
Comparison of Top RLHF Datasets
| Dataset | Release Date | Size | License/Type | Key Features | Source |
|---|---|---|---|---|---|
| HelpSteer3-Preference | May 2025 | 40,000+ human-annotated preference samples | CC-BY-4.0 / Human-annotated | Diverse tasks and languages | arxiv.org/abs/2505.11475 |
| PIKA | October 2025 | Synthetic (data-efficient) | Synthetic / Expert-level | Post-training alignment from scratch | arxiv.org/abs/2510.06670 |
| HelpSteer2 | June 2024 | 10,000 response pairs | Open-source | SOTA performance on benchmarks | arxiv.org/abs/2406.08673 |
| NIFTY Financial News Headlines | May 2024 | Curated headlines with metadata | N/A / Domain-specific | Financial forecasting, metadata-rich | arxiv.org/abs/2405.09747 |
Risk-Averse Strategies for Marketplace Sourcing
Approaching onchain sourcing mirrors stress-testing portfolios: probe for cracks before commitment. Prioritize datasets with documented quality controls, as Keymakr's 2025 guide outlines best practices in LLM annotation, from inter-annotator agreement to bias audits. GitHub's Awesome RLHF repository catalogs methods, but real prudence lies in verifying relevance to your fine-tuning vector, be it general assistance or niche forecasting.
Label Studio's workflows for RLHF datasets highlight tools for in-house validation, yet marketplaces accelerate this with pre-vetted options. RLTHF's hybrid human-AI annotation reduces costs without sacrificing fidelity, a model increasingly tokenized onchain. Developers must weigh licensing against commercial intent; perpetual royalties incentivize creators, but lock-in risks lurk in restrictive terms.
Armed with this checklist, developers can navigate onchain AI dataset marketplaces with the precision of a hedged position, minimizing exposure to subpar data that could derail fine-tuning efforts. Platforms like FineTuneMarket. com exemplify this maturity, tokenizing premium fine-tuning datasets for instant, secure acquisition while embedding royalties that sustain creator incentives. Yet, the true test lies in post-purchase validation, where synthetic benchmarks meet real-world prompts to expose latent weaknesses.
Validating Dataset Integrity Before Deployment
Once sourced, dissect your RLHF datasets for LLM fine-tuning through layered stress tests, much like probing derivatives for tail risks. Compute inter-annotator agreement scores above 0.85 Kappa; anything less signals discord that reward models will amplify. Scrutinize diversity metrics, ensuring coverage across languages, domains, and edge cases, as HelpSteer3-Preference demonstrates with its multilingual breadth. Tools from Label Studio or AWS preference pipelines facilitate this, but integrate blockchain provenance queries to confirm no tampering en route from marketplace to your pipeline.
Opinion tempers haste here: I've seen institutions burn millions on 'premium' data mirages that collapsed under production loads. Prioritize datasets like PIKA for their data-efficient proofs, where fewer samples yield outsized alignment gains, but cross-validate against NIFTY-style domain data if your LLM targets finance. This hybrid vigilance transforms commodities into strategic assets.
Secure RLHF Dataset Validation: Audit, Diversify, Benchmark, Sandbox
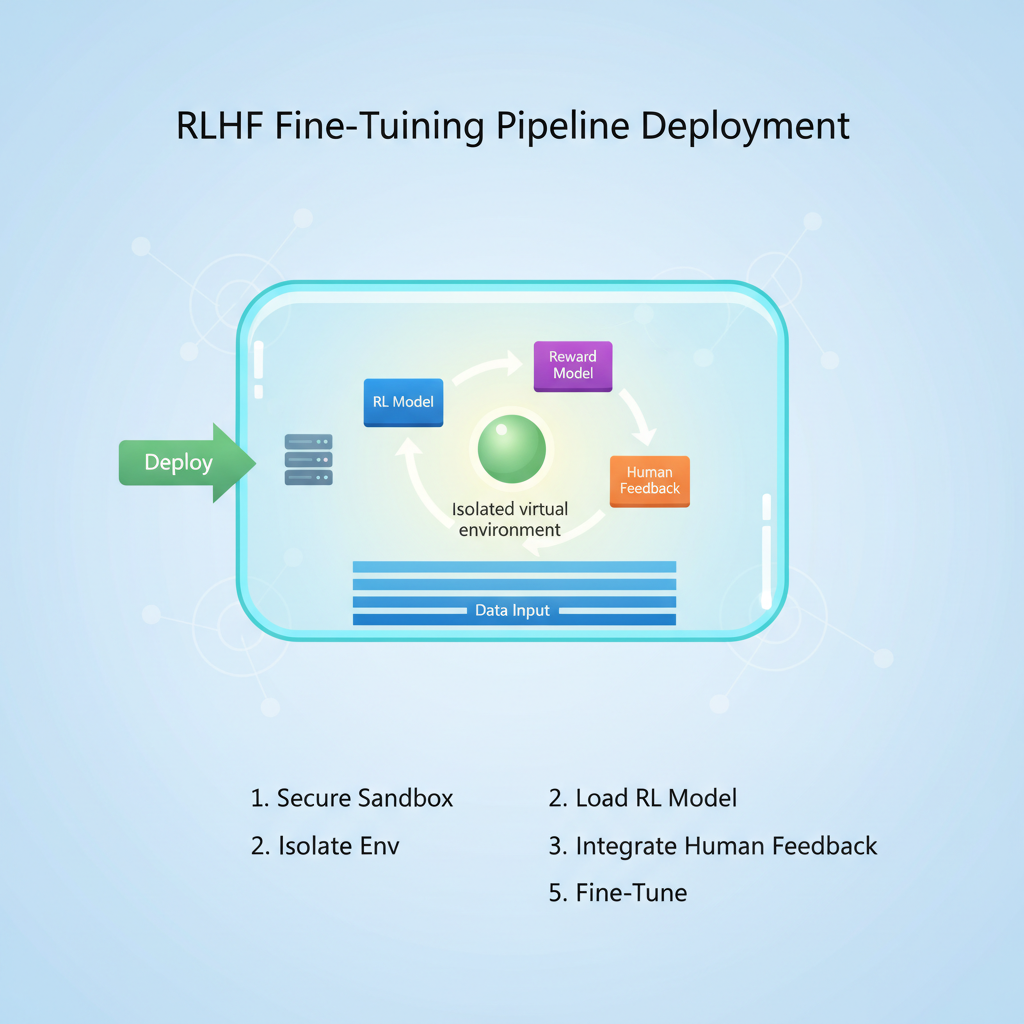
Case Studies: Real-World Wins from Onchain Sourcing
Enterprises leveraging onchain AI dataset marketplaces report 30-50% faster convergence in RLHF loops, per MLOps community anecdotes. One fintech firm paired NIFTY headlines with HelpSteer2 pairs, birthing a forecasting LLM that edged out baselines by 12% on accuracy, all while royalties flowed back to curators via smart contracts. Another startup, constrained by compute, adopted PIKA's synthetics and scaled to production in weeks, sidestepping the annotation drudgery outlined in Keymakr's guide.
These aren't anomalies; they underscore Reinforcement Learning Human Feedback data's leverage when provenance-assured. iMerit's symbiosis of annotation and RLHF shines through, as human preferences distilled onchain outmaneuver off-chain opacity. Yet, caution prevails: over-reliance on any single dataset invites model monoculture, vulnerable to evolving benchmarks.
Sourcing Premium RLHF Datasets via Onchain Marketplaces: 2026 Guide
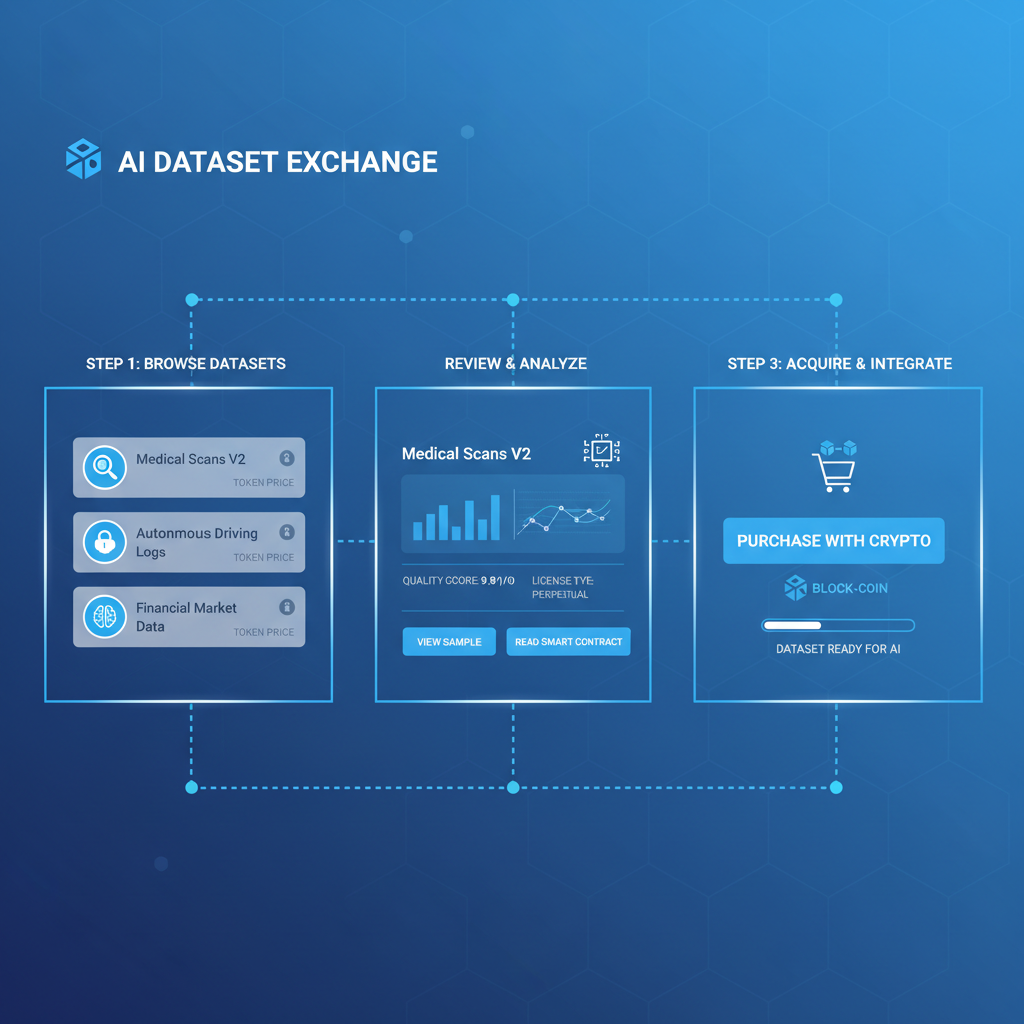
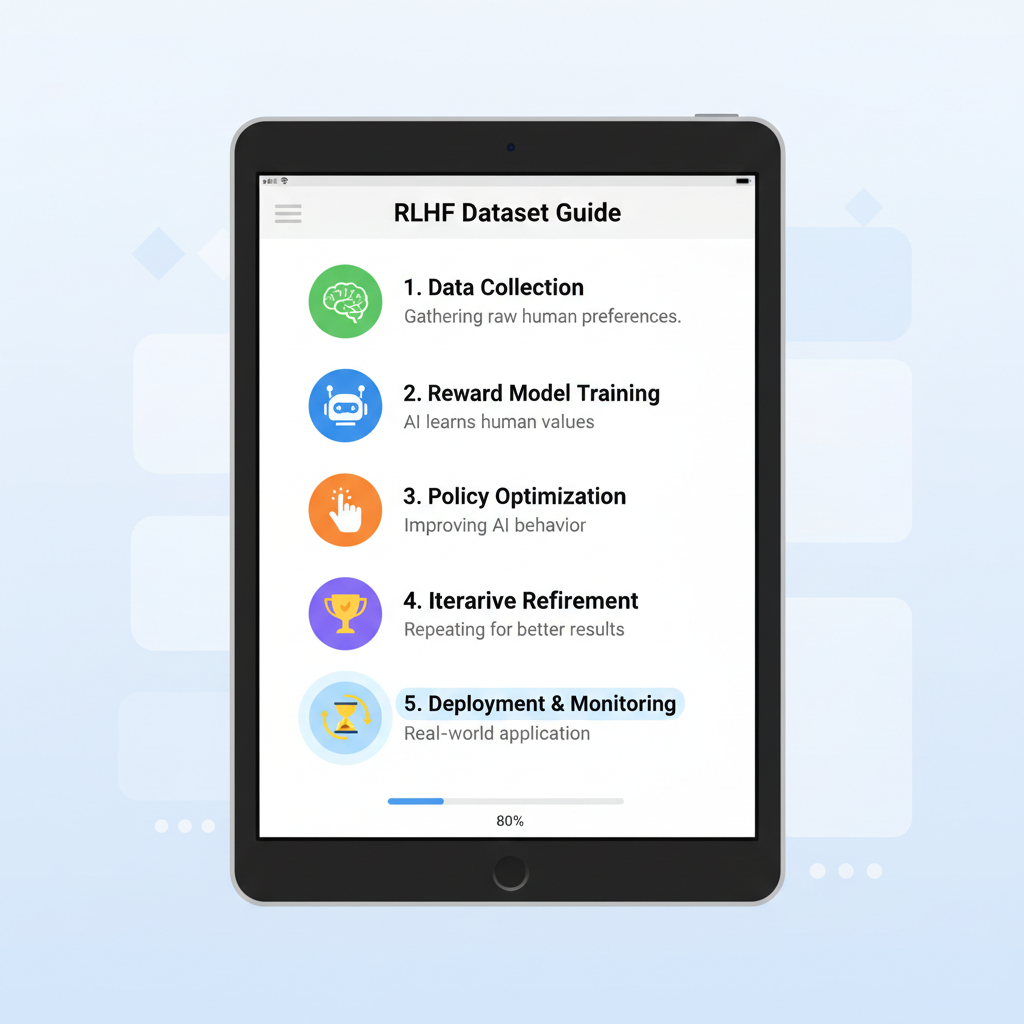



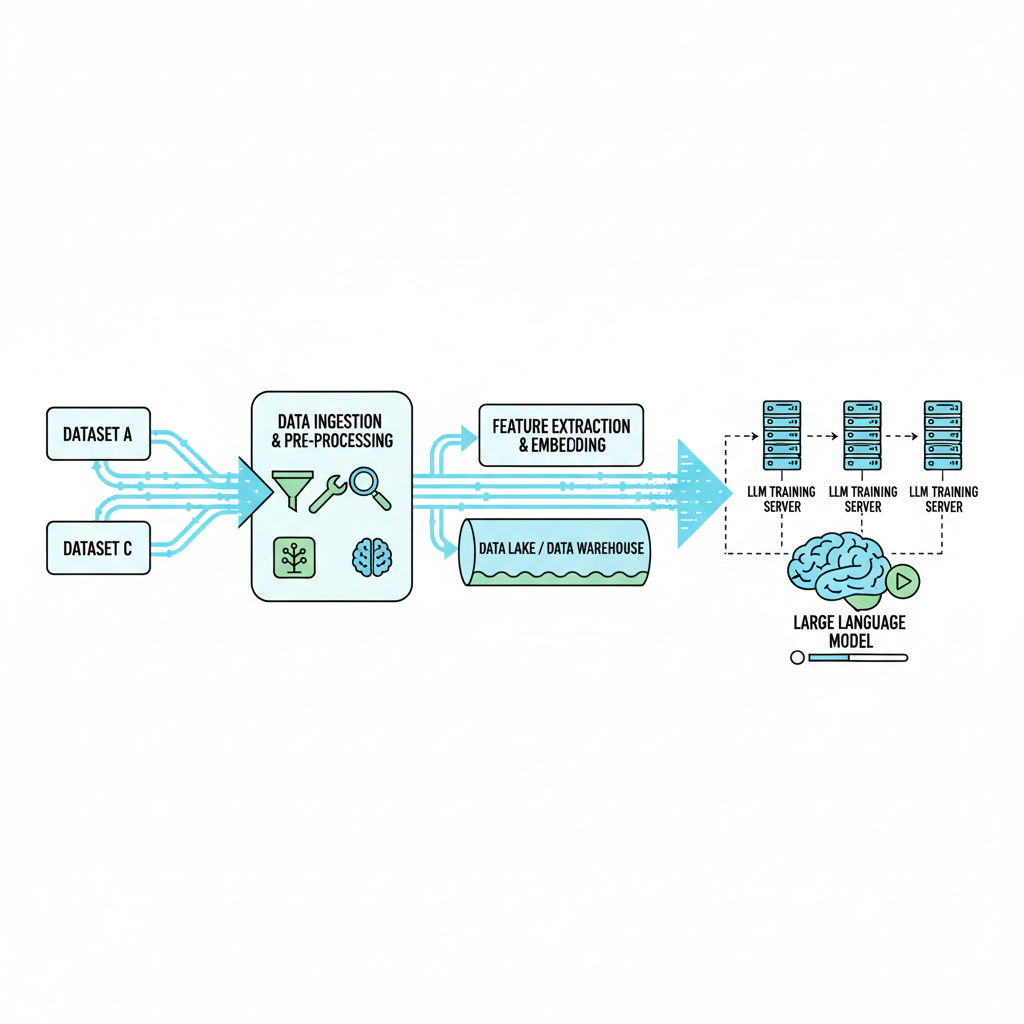
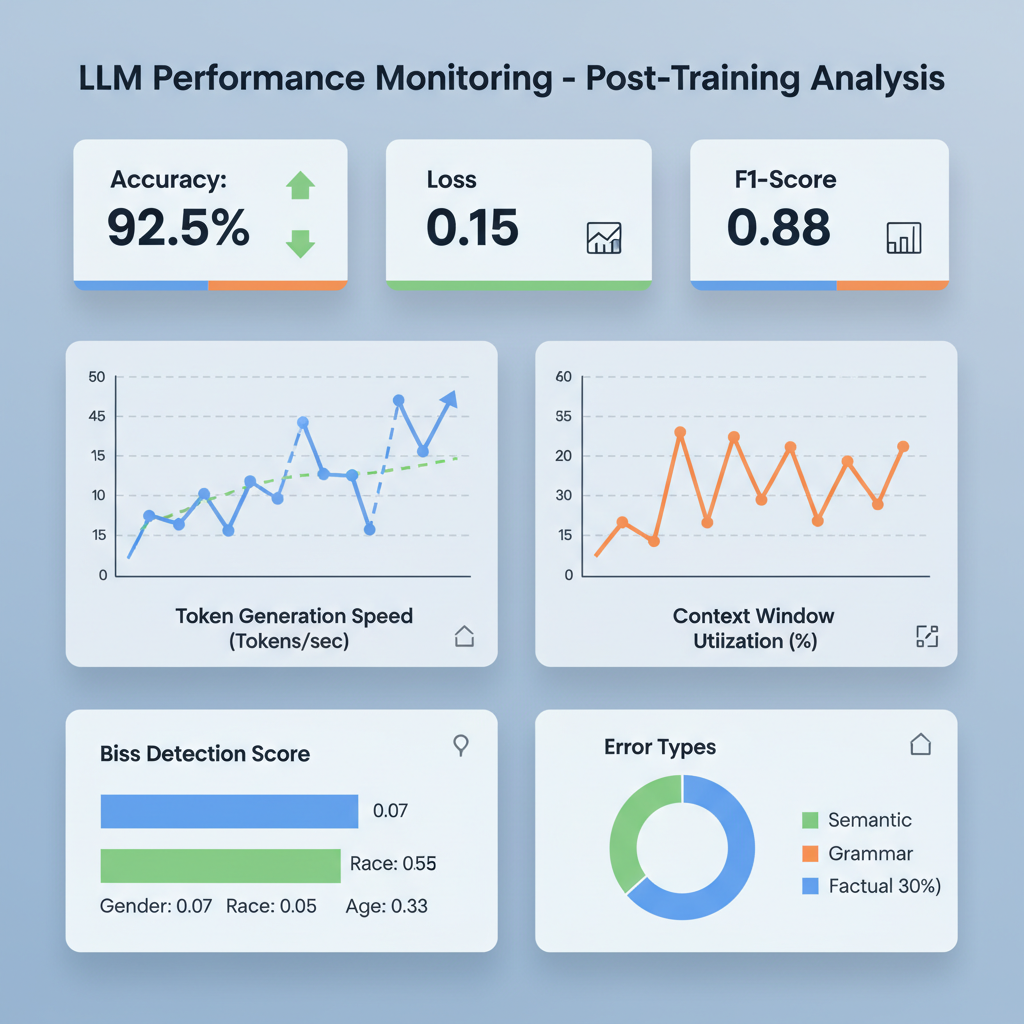
Future-Proofing Your Sourcing Strategy
By 2027, expect hybrid datasets blending RLTHF's targeted feedback with onchain oracles for real-time quality signals, further entrenching marketplaces like FineTuneMarket. com. Developers eyeing premium fine-tuning datasets buy options should bake in scalability clauses, anticipating LLM parameter explosions that devour data at terabyte scales. My mantra holds: protect alignment first, performance accrues.
GitHub's Awesome RLHF evolves alongside, curating open methods that complement proprietary buys. For those venturing into custom annotation, outsource to vetted LLM data annotation services with onchain audit trails, but always retain veto power over final merges. This disciplined fusion of marketplaces, tools, and skepticism equips teams to harness annotated datasets for AI models without courting catastrophe.
Onchain sourcing isn't a panacea, but wielded astutely, it fortifies LLMs against the wilds of preference optimization, yielding robust, trustworthy intelligence that endures.




No comments yet. Be the first to share your thoughts!