When fine-tuning beats RAG for specific tasks
Retrieval-Augmented Generation (RAG) is the standard for keeping models up-to-date with external facts, but it struggles with behavioral consistency. RAG can inject information, but it cannot reliably force a model to adopt a specific tone, follow complex structural rules, or internalize proprietary logic. When your application requires the model to behave a certain way rather than just know certain facts, fine-tuning is often the superior path.
In 2026, the barrier to entry for fine-tuning has collapsed. Techniques like LoRA and QLoRA allow developers to adapt large language models on consumer-grade hardware without retraining from scratch. This shift means you no longer need massive cloud budgets to customize a model for niche tasks like legal contract review or specific API response formatting.
For developers using tools like Axolotl or Hugging Face, the decision comes down to latency and consistency. A fine-tuned model responds faster because it doesn’t need to process large document chunks at inference time. More importantly, it reduces hallucination rates for structured outputs. If your primary keyword cluster revolves around cost-effective, local hardware feasibility, fine-tuning offers a predictable, one-time compute cost that RAG’s recurring retrieval overhead often cannot match.
Cloud platforms for quick fine-tuning
Managed cloud platforms bridge the gap between raw GPU power and developer convenience. Instead of configuring Kubernetes clusters or wrestling with driver compatibility, you upload your dataset and let the platform handle the orchestration. This approach is particularly effective for the 2026 trend of cost-efficient fine-tuning, where managing a 7B model can cost under $5.
The landscape of managed fine-tuning has shifted from general-purpose ML platforms to specialized tooling. The following platforms are currently the most practical for developers who need speed without the infrastructure overhead.
Hugging Face
Hugging Face remains the central hub for the open-source community. Its platform allows you to fine-tune models directly from the web interface or via API, supporting a vast library of base models including Llama, Qwen, and Mistral. The primary advantage is integration; you can push your fine-tuned models straight back to the Hub, making them immediately available for inference or further community iteration.
Axolotl
Axolotl has emerged as a favorite for developers who want the flexibility of local training scripts but the scalability of the cloud. It is a configuration-based framework that supports advanced techniques like QLoRA and DPO. While it started as a local tool, its cloud integrations allow you to spin up ephemeral GPU instances that tear down automatically after training, preventing cost overruns from forgotten jobs.
SiliconFlow
SiliconFlow offers a streamlined API-focused experience designed for rapid iteration. It is particularly strong for developers who want to fine-tune open-source models like Llama and Qwen without managing the underlying compute. The platform abstracts away the complexity of distributed training, allowing you to focus on data quality and prompt engineering.
Firework AI
Firework AI specializes in high-performance inference and fine-tuning for large language models. It is optimized for speed, making it a strong choice if you are fine-tuning for low-latency production environments. Their platform handles the heavy lifting of model optimization, ensuring your fine-tuned models run efficiently on their infrastructure.
LLaMA-Factory
LLaMA-Factory provides a comprehensive GUI and command-line interface for fine-tuning a wide variety of open-source models. It supports multiple training algorithms and is highly configurable. While it can be run locally, its cloud-ready nature makes it easy to deploy on managed infrastructure for those who prefer a more hands-on approach than pure API services.
| Platform | Pricing Model | Ease of Use |
|---|---|---|
| Hugging Face | Pay-per-job | High |
| Axolotl | Pay-per-GPU-hour | Medium |
| SiliconFlow | API credits | High |
| Firework AI | Usage-based | Medium |
| LLaMA-Factory | Flexible | Medium |
Open-source frameworks for local control
Best LLM Fine-Tuning Tools for works best as a clear sequence: define the constraint, compare the realistic options, test the tradeoff, and choose the path with the fewest hidden costs. That order keeps the advice usable instead of decorative. After each step, pause long enough to check whether the recommendation still fits the reader's actual situation. If it depends on perfect timing, unusual access, or a best-case budget, include a simpler fallback.
The simplest way to use this section is to write down the real constraint first, compare each option against it, and choose the path that still works outside ideal conditions.
Hardware and GPU requirements explained
Best LLM Fine-Tuning Tools for works best as a clear sequence: define the constraint, compare the realistic options, test the tradeoff, and choose the path with the fewest hidden costs. That order keeps the advice usable instead of decorative. After each step, pause long enough to check whether the recommendation still fits the reader's actual situation. If it depends on perfect timing, unusual access, or a best-case budget, include a simpler fallback.
The simplest way to use this section is to write down the real constraint first, compare each option against it, and choose the path that still works outside ideal conditions.
Dataset Preparation Tools
Your fine-tuning results are only as good as the data you feed them. Before you touch a single hyperparameter, you need to clean, format, and validate your training corpus. In 2026, the most efficient workflows rely on tools that integrate directly into your existing pipeline without requiring heavy infrastructure.
Hugging Face Datasets
The Hugging Face datasets library remains the standard for loading and preprocessing data at scale. It allows you to stream large datasets directly from the Hub, saving disk space and memory. You can apply transformations like tokenization or filtering using Python functions, making it highly flexible for custom cleaning tasks. For most developers, this is the starting point for any fine-tuning project.
Axolotl Data Formatting
Axolotl simplifies the often tedious process of formatting datasets for specific instruction-tuning formats. Its configuration files allow you to map your raw data columns to the expected prompt-response structure with minimal code. This reduces the risk of formatting errors that can cause training instability. If you are using Axolotl for training, leveraging its built-in data handlers ensures your dataset is ready for immediate consumption.
Local Data Cleaning
For smaller datasets, local tools like Pandas or simple Python scripts are often faster and more cost-effective than cloud-based annotation platforms. Since you are likely running these tasks on your own hardware, keeping the data preparation local avoids unnecessary API costs and latency. Focus on removing duplicates, filtering out low-quality samples, and ensuring consistent formatting before you begin training.
Checklist for your first fine-tuning project
Before committing to a specific tool, run through this five-step workflow. It ensures your project is feasible on your hardware and aligned with your business goals.

Be specific about the problem. Are you trying to fix hallucinations, enforce a strict JSON output format, or inject domain-specific knowledge? If the task can be solved with prompt engineering or Retrieval-Augmented Generation (RAG), skip fine-tuning to save compute costs.
Quality beats quantity. Start with a high-quality dataset of 500 to 1,000 examples. Use a tool like Axolotl to format your data into a consistent instruction-response pair structure. Remove noisy or irrelevant samples, as they will confuse the model.
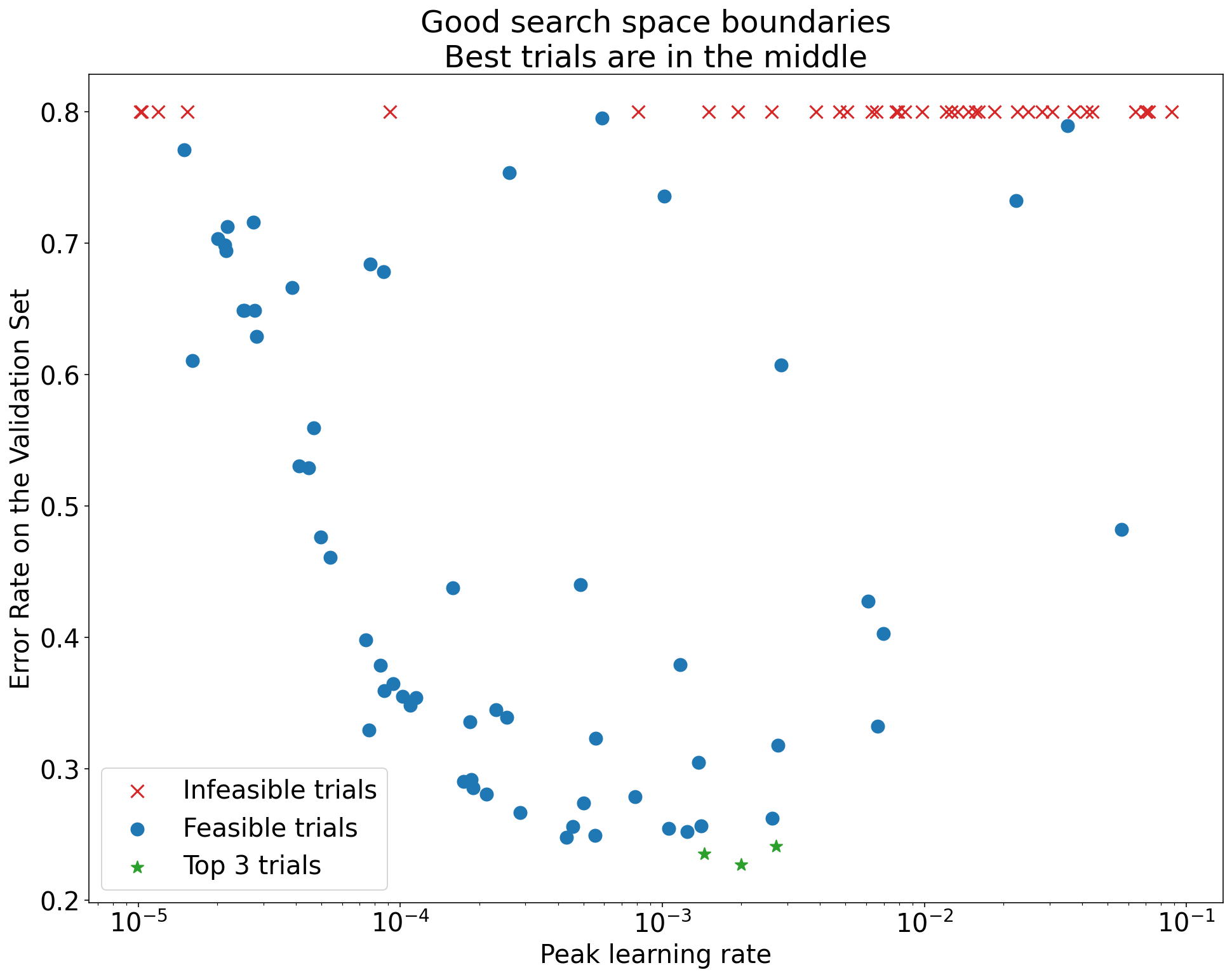
Select a foundation model that matches your language and capability needs. For most 2026 projects, a 7B or 13B parameter model is the sweet spot for balancing performance and inference speed. Ensure the model is open-weight and supports the fine-tuning method you plan to use.
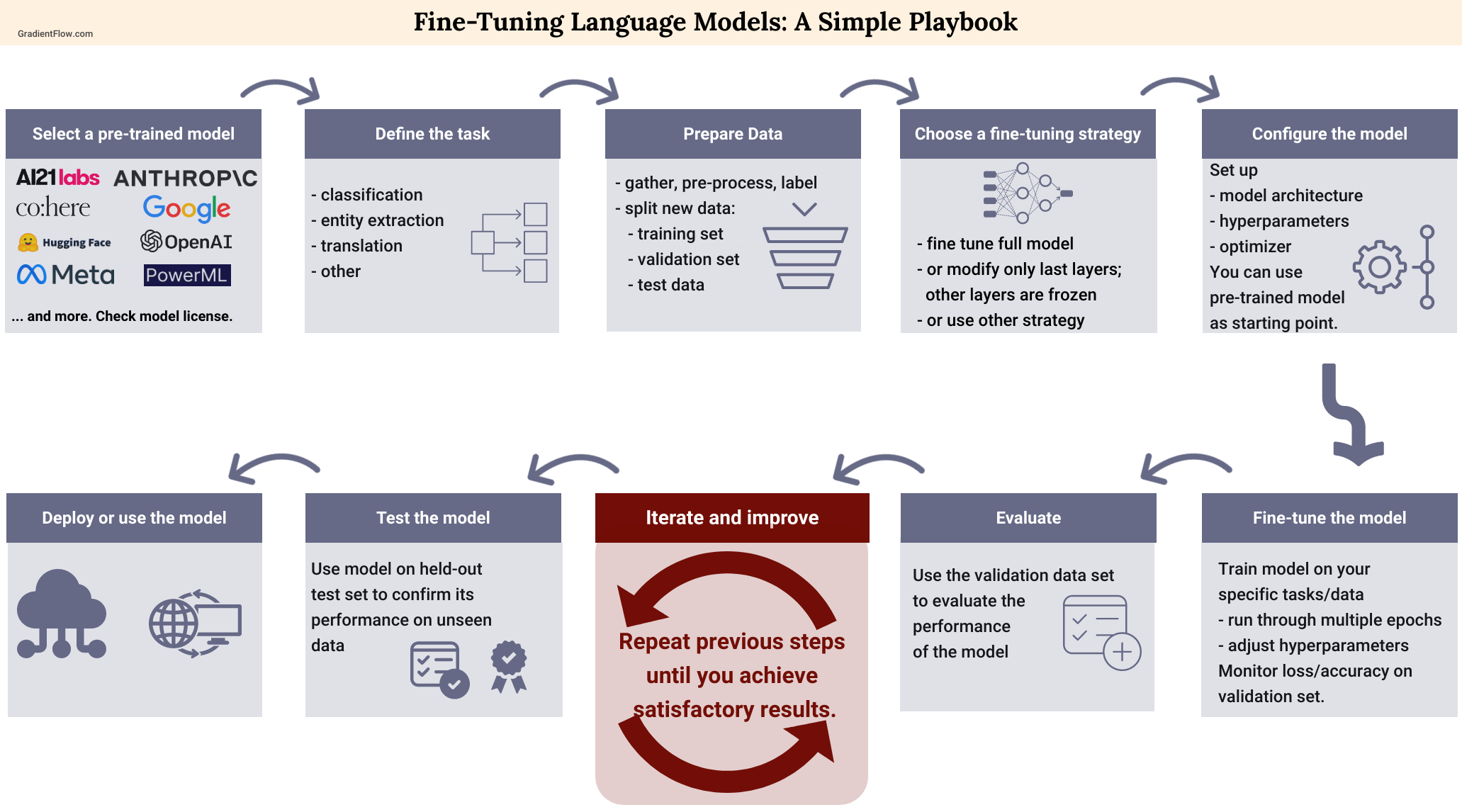
Use Low-Rank Adaptation (LoRA) or Quantized LoRA (QLoRA) to reduce memory requirements. These techniques allow you to fine-tune large models on consumer-grade GPUs without training the entire network. This is the most cost-effective approach for developers in 2026.

Do not train on your full dataset immediately. Run a quick trial on 100 examples to verify that your pipeline works and that the loss is decreasing. If the model fails to learn from this small subset, fix your data formatting before scaling up.
Common questions about LLM fine-tuning
The barrier to entry for fine-tuning has dropped significantly, but confusion remains around hardware requirements and method selection. Here are the most frequent technical doubts developers face in 2026.
Helpful gear
Use these product recommendations as a starting point, then choose the size, material, and price point that fit how you actually use the gear.


As an Amazon Associate, we may earn from qualifying purchases.
No comments yet. Be the first to share your thoughts!