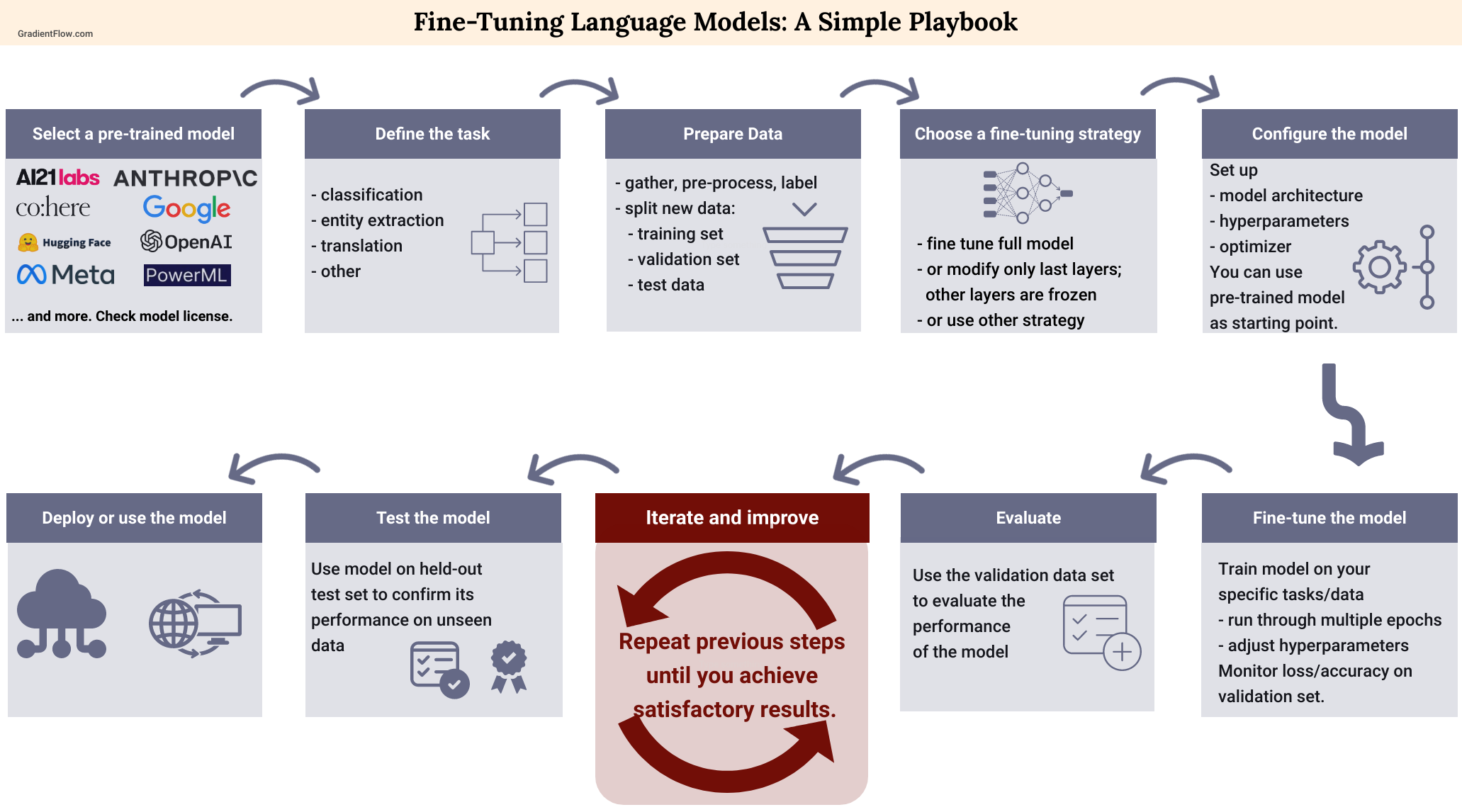
The 2026 Fine-Tuning Landscape
The enterprise approach to customizing large language models has shifted decisively away from full fine-tuning. In 2026, updating every parameter in a base model is widely recognized as an inefficient use of capital. It requires massive GPU clusters, extends training cycles from hours to days, and carries a high risk of catastrophic forgetting, where the model loses its general reasoning abilities while adapting to narrow tasks.
Parameter-efficient fine-tuning (PEFT) has become the standard for cost control. Methods like LoRA and QLoRA allow organizations to inject trainable layers into a frozen model, reducing memory requirements by up to 90% while maintaining comparable performance on specialized tasks. This shift enables teams to fine-tune models on consumer-grade hardware or small cloud instances, turning what was once a capital-intensive infrastructure project into a routine operational expense.
The modern stack for 2026 relies on Python 3.11+, PyTorch 2.5+, and CUDA 12.x, anchored by the Hugging Face ecosystem. Tools like peft, transformers, and trl have matured to the point where PEFT workflows are often simpler to implement than full training pipelines. For finance and market analysis teams, this efficiency means faster iteration cycles and lower costs per experiment, making fine-tuning a viable strategy for handling proprietary data without the overhead of maintaining large-scale training clusters.
PEFT vs Full Fine-Tuning Costs
The 2026 fine-tuning stack centers on Python 3.11+, PyTorch 2.5+, and the Hugging Face ecosystem. Within this infrastructure, the choice between Parameter-Efficient Fine-Tuning (PEFT) and full fine-tuning is primarily a calculation of capital expenditure against performance necessity. Full fine-tuning, which updates all of a base model’s parameters, is almost never the right answer for enterprise applications in 2026. It is expensive, risks catastrophic forgetting, and requires hardware configurations that rarely justify the marginal gains over specialized retrieval methods.
PEFT methods, such as Low-Rank Adaptation (LoRA), insert trainable layers into the model while freezing the pre-trained weights. This approach reduces the number of trainable parameters by orders of magnitude, allowing enterprises to run fine-tuning on consumer-grade GPUs or smaller cloud instances. The cost savings are not merely incremental; they are structural, shifting the burden from massive GPU clusters to scalable, cost-efficient compute.
The table below compares the operational realities of these approaches. Note that "Performance" reflects the capability to learn new domains versus retaining general knowledge.
| Method | Relative Cost | Hardware Requirement | Performance Tradeoff |
|---|---|---|---|
| Full Fine-Tuning | High | Multi-GPU Cluster (A100/H100) | High domain adaptation, high forgetting risk |
| LoRA (PEFT) | Low | Single GPU (24GB+ VRAM) | High domain adaptation, low forgetting risk |
| Q-LoRA (PEFT) | Very Low | Single GPU (12GB+ VRAM) | Good domain adaptation, minor quality loss |
| RAG (No Fine-Tuning) | Minimal | CPU or Small GPU | Dependent on retrieval quality, no model change |
For most enterprise use cases, the ROI of PEFT is clear. The infrastructure required for full fine-tuning often exceeds the budget of mid-sized deployments. By contrast, PEFT allows for rapid iteration and lower operational costs, making it the standard for most 2026 applications where domain-specific knowledge is required without the expense of retraining the entire foundation model.
When RAG Replaces Fine-Tuning
The primary differentiator between Retrieval-Augmented Generation (RAG) and fine-tuning is scope: RAG updates what a model knows, while fine-tuning changes how it speaks. For most enterprise applications involving factual accuracy or dynamic data, RAG is the more cost-efficient strategy. Fine-tuning a large language model adapts a general-purpose base to a specific task, but it permanently encodes knowledge into the model's weights, making it expensive to update and prone to hallucination when data changes.
Full fine-tuning—updating all of a base model's parameters—is rarely the right answer in 2026. It requires significant computational resources and risks catastrophic forgetting, where the model loses its general reasoning abilities. Instead, enterprises should reserve fine-tuning for style adaptation, specific instruction tuning, or domain-specific reasoning patterns that cannot be achieved through prompts alone. For everything else, RAG offers a cheaper, more maintainable path.
From an ROI perspective, RAG eliminates the recurring costs of retraining. When product catalogs, compliance rules, or internal policies change, you simply update the vector database. Fine-tuning requires re-running the entire training pipeline, which is both time-consuming and costly. If your use case does not require the model to adopt a new dialect or reasoning framework, RAG provides higher accuracy with lower infrastructure spend.
Infrastructure and hardware costs
Use this section to make the Fine-Tuning LLMs decision easier to compare in real life, not just on paper. Start with the reader's actual constraint, then separate must-have requirements from details that are merely nice to have. A practical choice should survive normal use, maintenance, timing, and budget. If a recommendation only works in an ideal situation, call that out plainly and give the reader a fallback path.
The simplest way to use this section is to write down the must-have criteria first, then compare each option against those criteria before weighing nice-to-have features.
Enterprise ROI decision checklist
Use this section to make the Fine-Tuning LLMs decision easier to compare in real life, not just on paper. Start with the reader's actual constraint, then separate must-have requirements from details that are merely nice to have. A practical choice should survive normal use, maintenance, timing, and budget. If a recommendation only works in an ideal situation, call that out plainly and give the reader a fallback path.
-
Verify the basicsConfirm the core specs, condition, and fit before comparing extras.
-
Price the downsideLook for the repair, maintenance, or replacement cost that would change the decision.
-
Compare alternativesCheck at least two comparable options before treating one listing as the benchmark.
No comments yet. Be the first to share your thoughts!